MIT’s SpAtten Architecture Uses Attention Mechanism for Advanced NLP
March 11, 2021
Story

Processing of human-generated textual data has always been an important yet challenging task, as human language tends to be naturally robust for machines to understand.
Still, there have been many efficient NLP models like Google’s BERT and Open AI’s GPT2, which function to understand this data through advanced processing and computations. These models find their application in search engines, as the search commands need to be matched with relevant sources and pages, irrespective of the nature of terms.
MIT’s SpAtten learning system focuses on efficient search predictions through its optimized software-hardware design for advanced natural language processing with less computing power. Thus, the architecture of the SpAtten system replaces the combination of high-end CPUs and GPUs which together output an efficiency similar to MIT’s SpAtten learning system.
Attention Mechanism in SpAtten Learning System
Attention mechanism plays a crucial role in natural language processing when the data is extensive and large in amount. Especially, where the textual data consists of various features that might not be very important for modeling. This can squander the overall computation of the system. Hence, the attention mechanism in the input layer of the neural network dynamically extracts the relevant features from the textual data, which can optimize the processing of algorithms on an extensive dataset.
Source: https://arxiv.org/pdf/2012.09852.pdf
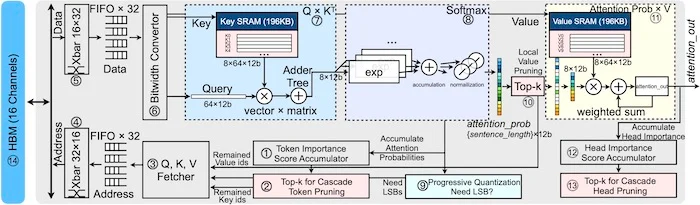
SpAtten uses the attention mechanism algorithms to remove the words which have less weightage in terms of NLP. Thus, it selectively picks the relevant keywords from the input textual data. This avoids the real-time processing of unnecessary textual data, hence saving the overall computational time of the system. However, this kind of processing provides efficiency and accuracy, but it comes at the cost of well-designed hardware compatible with such complex algorithms.
Thus MIT has worked on both, the software and the hardware aspect of its new SpAtten learning system. The designed hardware is dedicated to optimizing these complex algorithms to reduce processing and memory access. These techniques when used on textual data overcome the challenge of building a system with efficient processing speed and power. Hence, the hardware “enables streamlined NLP with less computing power.”
Optimization Techniques for SpAtten’s Architecture
The recurrent and convolutional neural networks are considered to be ideal for deep learning models, but MIT’s research paper on “SpAtten: Efficient Sparse Attention Architecture with Cascade Token and Head Pruning” has brought to our attention that attention mechanism can perform better than these networks, as discussed in the previous part.
Source: https://arxiv.org/pdf/2012.09852.pdf
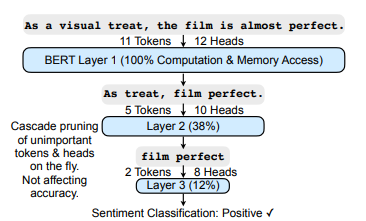
The architecture supports the cascade pruning technique, which operates on the tokens and heads instead of the weights that were used in conventional methods. As the term “pruning” suggests the removal of tokens, once a token/head is removed from the layer then it will never be processed in the subsequent layers as it is permanently “pruned” or removed from the system. This is why the real-time processing of data is optimized and the system is adaptive to the input instances.
The system uses the progressive quantization technique for the reduction of DRAM access. This technique operates on the LSB’s only if the MSB’s are not enough to perform quantization. However, this comes at the cost of computation but the memory access is significantly decreased. Hence, it makes the attention layers dynamic and adaptive for optimization of DRAM access. The system also comes with inbuilt SRAM for storing removed tokens which can be reused across numerous queries.
The generalized AI accelerators, GPUs, TPUs, and NPUs cannot implement these techniques even if they support high computational abilities, as these components are only capable of enhancing the existing conventional neural networks including CNNs and RNNs. Therefore, MIT designed specialized hardware to implement these optimized algorithms.
SpAtten Learning System’s Analysis
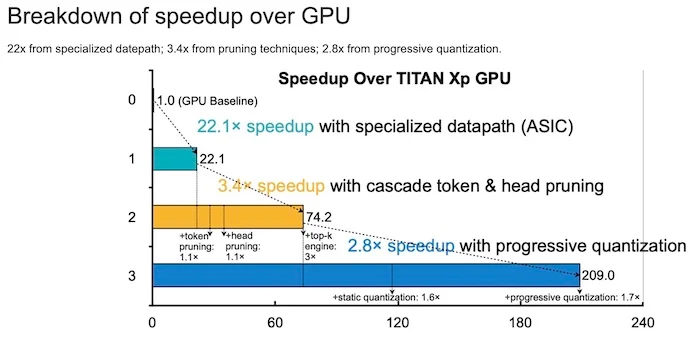
The simulation of SpAtten’s hardware architecture unveiled its high processing power against its competing processors. MIT says “SpAtten runs more than 100 times faster than the next best competitor (a TITAN Xp GPU). Also, SpAtten is more than 1,000 times more energy-efficient than its competitors, indicating that SpAtten could help trim NLP’s substantial electricity demands.”
Source: https://arxiv.org/pdf/2012.09852.pdf
Google’s BERT and Open AI’s GPT2 models also use a similar kind of attention mechanism but, the complex discriminative and generative techniques cause latencies and delays. MIT's SpAtten is a combination of NLP algorithm and specialized hardware dedicated to attention mechanism. This combination controls the high power consumption that standard CPUs consume while operating on GPT-2 or BERT.
For more information visit the official press release from MIT.

Saumitra Jagdale is a Backend Developer, Freelance Technical Author, Global AI Ambassador (SwissCognitive), Open-source Contributor in Python projects, Leader of Tensorflow Community India, and Passionate AI/ML Enthusiast.