
The many uses of RTOS message queues
October 04, 2017
Story

An application can have any number of message queues, each one having its own purpose.
An RTOS is software that manages the time of a central processing unit (CPU), a microprocessing unit (MPU), or even a digital signal processor (DSP) as efficiently as possible. Most RTOS kernels are written in C and require a small portion of code written in ASSEMBLY language to adapt the kernel to different CPU architectures.
An RTOS kernel provides many useful services to a programmer, such as multitasking, interrupt management, inter-task communication through message queues, signaling, resource management, time management, memory partition management, and more.
The application (i.e., end product) is basically split into multiple tasks, each one responsible for a portion of the application. A task is a simple program that thinks it has the CPU all to itself. Each task is assigned a priority based on the importance of the task.
What are message queues?
As shown in Figure 1, a message queue is a kernel object (i.e., a data structure) through which messages are sent (i.e., posted) from either interrupt service routines (ISRs) or tasks to another task (i.e., pending). An application can have any number of message queues, each one having its own purpose. For example, a message queue can be used to pass packets received from a communication interface ISR to a task, which in turn would be responsible for processing the packet. Another queue can be used to pass content to a display task that will be responsible for properly updating a display.
 Figure 1. Message queues are kernel objects used to pass content to a task.
Figure 1. Message queues are kernel objects used to pass content to a task.Messages are typically void pointers to a storage area containing the actual message. However, the pointer can point to anything, even a function for the receiving task to execute. The meaning of the message is thus application-dependent. Each message queue is configurable in the amount of storage it will hold. A message queue can be configured to hold a single message (a.k.a., a mailbox) or N messages. The size of the queue depends on the application and how fast the receiving task can process messages before the queue fills up.
If a task pends (i.e., waits) for a message and there are no messages in the queue, then the task will block until a message is posted (i.e., sent) to the queue. The waiting task consumes no CPU time while waiting for messages since the RTOS runs other tasks. As shown in Figure 1, the pending task can specify a timeout. If a message is not received within the specified timeout, the task will be allowed to resume execution (i.e., unblock) when that task becomes the highest priority task. When the task executes it is basically told that the reason it was resumed was because of a timeout and thus didn’t get a message.
A message queue is typically implemented as first-in-first-out (FIFO), meaning that the first message received will be the first message extracted from the queue. However, some kernels allow you to send messages that are deemed more important than others, and thus post at the head of the queue. In other words, in last-in-first-out (LIFO) order, making that message the first one to be extracted by the task.
One important aspect of a message queue is that the message itself needs to remain in scope from the time it’s sent to the time it’s processed. This implies that you cannot pass a pointer to a stack variable, a global variable that could be altered by other code, and so on. To keep the message in scope, you would typically populate a structure that you would obtain from a pool of such messages, as shown in Figure 2. The ISR or task that sends the message would obtain a structure from the pool, populate the structure, and post a pointer to the structure to the queue. The receiving task would extract the pointer from the queue, process the structure, and when done, return the structure to the pool. Of course, both the sender and receiver need to use the same pool unless a field in the data structure indicates which pool was used.
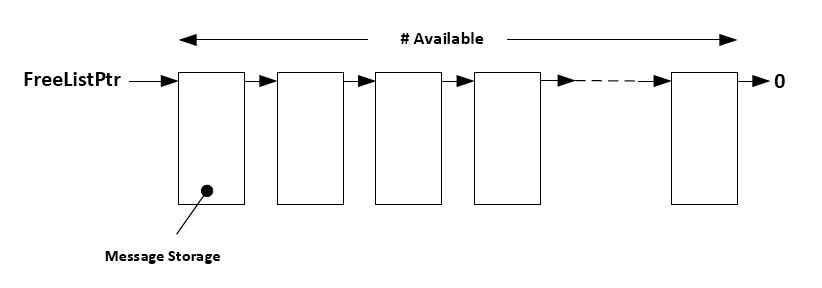
Figure 2. Pool of message storage areas
In many implementations of message queues in an RTOS, a message being sent to a queue is discarded if the queue is already full. Oftentimes this is not an issue and the logic of the application can recover from such situations. However, it’s fairly easy to implement a mechanism such that a sending task will block until the receiver extracts one of the messages, as shown in Figure 3:
- 1. The counting semaphore is initialized with a value corresponding to the maximum number of entries that the queue can accept.
- 2. The sending task pends on the semaphore before it’s allowed to post the message to the queue. If the semaphore value is zero, the sender waits.
- 3. If the value is non-zero, the semaphore count is decremented, and the sender post its message to the queue.
- 4. The recipient of the message pend one the message queue as usual.
- 5. When a message is received the recipient extracts the pointer to the message from the queue and signals the semaphore, indicating that an entry in the queue has been freed up.
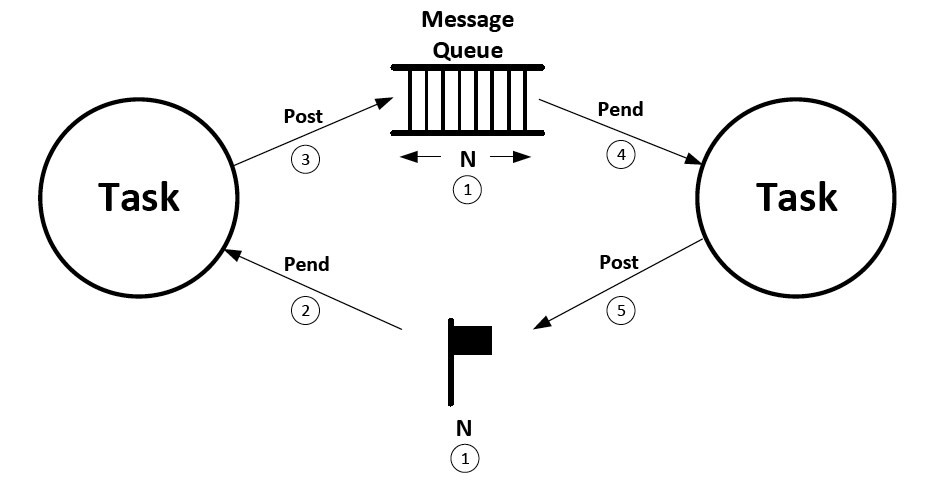
Figure 3. Blocking a sender if the queue is full.
As shown, this mechanism only works with two tasks because ISRs are not allowed to pend on a semaphore.
Other use of message queues
Figure 4 shows different use of message queues:
- 1-4. Message queues are typically used to send messages from an ISR or a task to another task, as previously discussed.
- 5. However, you don’t have to send an actual message and allocate storage area if the message fits within the word size of a pointer. For example, if a pointer is 32 bits wide then you can cast an analog to digital converter (ADC) reading from a 12-bit ADC to a pointer and send it through the message queue. As long as the recipient knows to cast the value back to an integer, it’s perfectly legal.
- 6-7. A task can use the timeout mechanism to delay itself for a certain amount of time if it knows that the messages will not be sent to it. In this case, a queue capable of holding a single entry would be sufficient. In fact, if another task or ISR sends a message, the delay would be aborted which could be the behavior you’d want to implement.
- 8. A message queue can be used as a semaphore to simply signal to a task that an event occurred. In this case, the message can be anything. The size of the queue would depend on how many signals the application would need to buffer.
- 9-10. A message queue can also be used either as a binary semaphore or a counting semaphore for resource sharing. For a binary semaphore, the queue would contain a single message, and a message (any value) would be placed in the queue. To access the resource, a task would pend on the queue. If there is a message in the queue, the task would gain access to the resource. Once done with the resource, the queue would be posted, thus relinquishing the resource for use by other tasks, as needed. The same mechanism applies to implementing a counting semaphore with N resources, and the queue would be pre-filled with N dummy messages.
- 11. Messages can actually be used to emulate event flags where each bit of a 32-bit pointer size variable (cast to an integer) can represent an event.
- 12. A message queue can be used to implement a stack structure. This is basically another use of the LIFO mechanism.
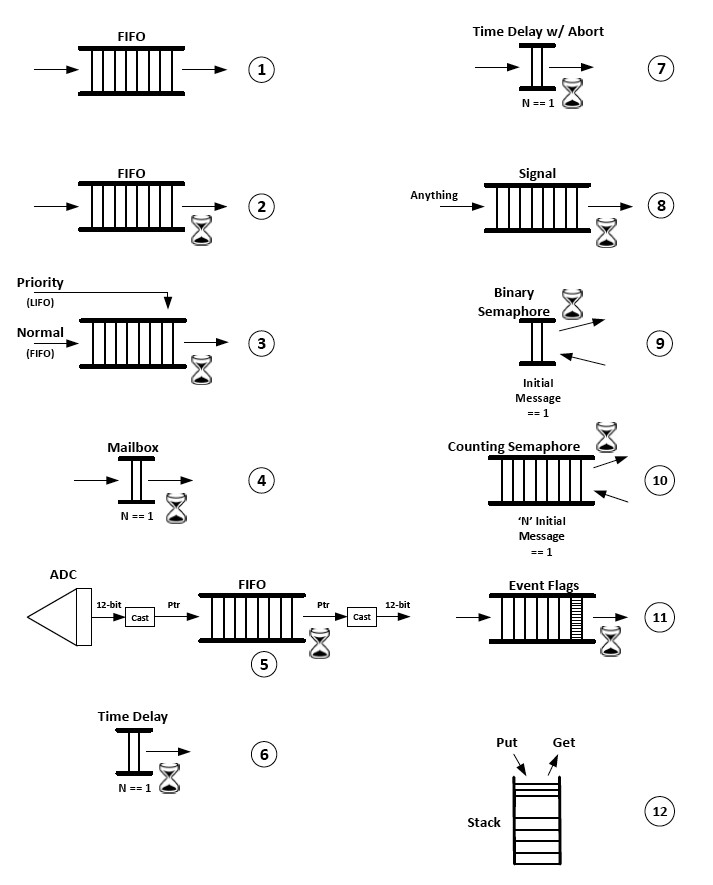
Figure 4. Some of the many uses of message queues.
Summary
Message queues can be used in a number of different ways. In fact, you can write fairly complex applications in which you might only use message queues. Using only message queues could reduce the size of your code (i.e., footprint) because many of the other services can be simulated (semaphores, time delays, and event flags).
Jean Labrosse founded Micrium in 1999 and continues to maintain an active role in product development as a software architect at Silicon Labs, ensuring that the company adheres to the strict policies and standards that make the RTOS products strong. Jean is a frequent speaker at industry conferences such as Embedded World, ARM TechCon, and the Embedded Systems Conference in Boston and Silicon Valley. He is the author of three definitive books on embedded design and the designer of the uC/OS series of RTOSs. He holds BSEE and MSEE degrees from the University of Sherbrooke, Quebec, Canada.



