
Understand the mobile graphics processing unit
September 16, 2014
Story

If implemented properly, a GPU within a mobile system can be a boon to performance. But that's a big "if."
If implemented properly, a GPU within a mobile system can be a boon to performance. But that’s a big “if.”
The mobile GPU or graphics processing unit is a dedicated co-processor designed to accelerate graphics applications, user interfaces, and 3D content on your smartphone, tablet, wearables, and IoT devices. Photorealistic 3D games and “live” graphical user interfaces (GUIs) are examples of workloads designed specifically for the GPU.
Several years ago, the GPU was a nice-to-have feature designed into high-end consumer mobile products that needed the latest technologies to retain their flagship status. Now, with graphical displays being ubiquitous and used on all sorts of connected devices, the GPU has become a necessary part of product specs for all mobile application processors and mid/high-end MCUs/MPUs. The GPU also helps product differentiation so companies can create compelling, visual-centric solutions for their target application.
The GPU is designed as a single instruction, multiple data (SIMD) processing engine built for massively parallel workloads. 3D graphics is one of the best examples of high throughput parallel processing since GPUs can process billions of pixels/vertices or floating-point operations (GFLOPS) every second. At the heart of the GPU are one or more shaders (SIMD units) that process independent vertices, primitives, and fragments (pixels). Shaders are computing elements that execute 3D graphics programs per-vertex, per-pixel, or other primitive basis.
Vertex shader programs modify object properties to enable control over position, movement, vertex lighting, and color. Pixel or fragment shader programs compute final pixel color, shadows, object texture, lighting, and can be programmed to add special effects to a scene with additions like blurring, edge enhancements, or filtering. There are also newer types of shader programs including geometry, tessellation, and compute shaders.
Compute shaders like those in OpenGL ES 3.1 are useful for advanced graphics rendering where you can blend 3D and GPU Compute (GPGPU) contexts to add real-life effects like physics processing (natural wave and wind motions or vivid explosions in a game) and global illumination (better lighting and shadows through computations involving direct and indirect light sources/rays). GPUs can also scale efficiently from one shader unit to thousands of interconnected, grouped shader units to increase performance and parallelism based on the target application ranging from IoT and mobile to high-performance computing (HPC) scientific computing. High-performance shader designs can run over 1.2 GHz and execute billions of instructions per cycle to process graphics, OpenCL, OpenVX (vision processing) and more.
Figure 1 shows some of the major differences between CPU and GPU architectures. Each design has its strong points and must work in tandem to achieve the most optimized solution (power, bandwidth, resource sharing, etc.). The best designs use a heterogeneous system architecture that splits/assigns workloads to each processing core based on its strengths. The GPU is also becoming an important part of the system as the industry moves toward platform-level optimizations where the GPU is used for computational intensive applications beyond graphics. Note that in today’s hybrid designs, there are other computational blocks including DSPs, FPGAs, and other task specific cores that can be used together with the CPU-GPU combination.

Figure 1
GPU pipeline introduction
Newer GPUs use “unified” shaders to achieve the best hardware resource management across different types of shader programs to balance workloads. The first versions of unified shaders combined vertex (VS) and pixel (PS) processing, with subsequent versions adding support for geometry (GS), tessellation (TS), and compute (CS) shaders as graphics APIs advanced.
For unified shaders, workloads assigned to each shader can either be vertex or pixel based, allowing the shader to switch between either contexts instantaneously to maintain a high level of shader utilization. This minimizes hardware resource bottlenecks and stalls in cases where you have a vertex- or pixel-heavy image. In non-unified shader architectures, there are separate, fixed VS and PS shaders. For example, if the image is vertex heavy, the VS can stall the GPU pipeline since it needs to finish before the GPU can continue processing the rest of the image. This causes pipeline bubbles and inefficient use of hardware. Figure 2 shows a case where you have separate VS and PS versus a unified shader core.

Figure 2
Over the years, GPU shaders have advanced beyond graphics to include general-purpose pipelines that can be configured for graphics, compute, image (ISP) co-processing, embedded vision, video (HEVC and H.264 pre/post-processing, etc.), and other parallel applications. This is why you hear terms like GPGPU (General Purpose GPU) and GPU Compute used to describe the broad use of GPUs outside of graphics rendering.
From a high level, the mobile GPU pipeline consists of multiple key blocks:
Host interface and (secure) MMU
- Communicates with the CPU through the ACE-Lite/AXI/AHB interfaces.
- Processes commands from the CPU and accesses geometry data from frame buffer or system memory.
- Outputs a stream of vertices that is sent to the next stage (vertex shader).
- Manages all GPU transactions including instruction/data dispatch to shaders, allocates/deallocates resources, and provides security for secure transactions and data compression.
Programmable unified shaders
- Vertex shaders (VS) include vertex transformation, lighting, and interpolation and can be simple (linear) to complex (morphing effects).
- Pixel/fragment shaders (PS) compute the final pixel value that take into account lighting, shadows, and other attributes, including texture mapping.
- Geometry shader (GS) takes a primitive (line, point or triangle) and modifies, creates (or destroys) vertices to increase an object’s level of detail. The GS lets the GPU pipeline access adjacent primitives so they can be manipulated as a closely knit group to create realistic effects where neighboring vertices interact with each other to create effects with smooth flowing motion (hair, clothes, etc.). The GS/VS/PS combination allows more autonomous GPU operation to handle state changes internally (minimize CPU-GPU interaction) by adding arithmetic and dynamic flow control logic to offload operations that were previously done on the CPU. Another key feature is Stream Out, where the VS/GS can output data directly to memory and the data can be accessed automatically and repeatedly by the shader unit or any other GPU block without CPU intervention. Stream Out is useful for recursive rendering (data re-use) on objects that require multiple passes, such as morphing of object surfaces and detailed displacement mapping.
- Tessellation shaders (TS) include two fixed-function units called the Hull and Domain shaders in the TS pipeline. The TS takes curved surfaces (rectangular or triangular) and converts them to polygon representations (mesh/patch) with varying counts that can be changed based on quality requirements. Higher counts create more detail and lower counts create less detail on an object. The tessellation unit is made up of three parts:
- Hull Shader (HS) is a programmable shader that produces a geometry (surface) patch from a base input patch (quad, triangle, or line) and calculates control-point data that’s used to manipulate the surface. The HS also calculates the adaptive tessellation factor which is passed to the tessellator so it knows how to subdivide the surface attributes.
- Tessellator is a fixed (configurable) function stage that subdivides a patch into smaller objects (triangles, lines, or points) based on the tessellation factor from the HS.
- Domain Shader (DS) is a programmable shader that evaluates the surface and calculates a new vertex position for each subdivided point in the output patch, which is sent to the GS for additional processing.
- Compute shader (CS) adds GPGPU/GPU compute capability to the graphics pipeline so developers can write GLSL application code that uses this shader and can run outside of the normal rendering pipeline. Data can be shared internally between pipeline stages and rendering-compute contexts so both can be executed in parallel. CS can also use the same contexts, status, uniforms, textures, image textures, atomic counters, etc. as the OpenGL/OpenGL ES rendering pipelines making it is easier and more straightforward to program and use together with the rendering pipeline output.
Programmable rasterizer
- Converts objects from geometric to pixel form and culls (removes) any back-facing or hidden surfaces. There are many levels of culling mechanisms to ensure that hidden pixels aren’t processed to save computation cycles, bandwidth, and power.
Memory interface
- Removes unseen or hidden pixels using the Z-buffer, stencil/alpha tests before writing pixels to the frame buffer.
- Compression including Z and color buffers is performed in this stage.
Immediate mode versus deferred-rendering GPUs
There are two common GPU architectures and methods of rendering an image. Both methods use the same general pipeline described earlier, but differ in the mechanism they use to draw. One method is called Tile Based Deferred Rendering (TBDR) and the other is Immediate Mode Rendering (IMR). Both have pros and cons based on their respective use cases.
In 1995 (before the days of smartphones/tablets), many graphics companies supported both methods in the PC and game console markets. The TBDR group had companies like Intel, Microsoft (Talisman), Matrox, PowerVR, and Oak. On the IMR side were names like SGI, S3, Nvidia, ATi, and 3dfx. Fast forward to 2014 – there are no TBDR architectures used in the PC and game console markets. All PC and console architectures, including the PS3/PS4, Xbox 360/One, and Wii, are IMR based.
The main reason for this transition was because of IMR’s inherent strength as an object rendering architecture that could handle very complex, dynamic game play (ex. fast motion, FPS, or racing games where scenes or viewpoints are constantly changing frame-to-frame). In addition, as 3D content triangle rates increased, TBDRs couldn’t keep up since they needed to continuously overflow their cache memories to frame buffer memory due to their architectural limitations. Higher triangle/polygon counts allow the GPU to render silky smooth and detailed (realistic) surfaces, instead of the blocky curved surfaces that appeared in legacy games. With the addition of tessellation shaders in IMR, surface rendering where triangles/polygons are further subdivided, brings 3D graphics even closer to reality.
Today’s mobile market closely mirrors the PC and game console market trends where IMR technology is replacing TBDR. In the TBDR market, you have two companies, Imagination and ARM, although ARM is trying to move toward IMR since they see major benefits when running next-gen games on mobile. On the IMR side you have Qualcomm, Vivante, Nvidia, AMD, and Intel.
A big benefit of going with IMR is that game/application developers can re-use and easily port their existing game assets already running on complex GPUs (or game consoles) to mobile devices. Since mobile devices have stringent limitations on power/thermal and die area, the best way to close the performance gap and minimize application porting or significant code changes is to use a similar architecture to what they develop on. IMR gives developers that choice in addition to getting equivalent, high-quality PC quality rendering, all packed into a smaller die area than TBDR solutions. IMR also improves internal system and external memory bandwidth as the industry moves beyond OpenGL ES 3.1 and DirectX 12 application programming interfaces (API).
Finally, TBDR architectures are optimized for low triangle/polygon count 3D content and simple user interfaces. IMR architectures excel when it comes to dynamic user interfaces and detailed 3D content that bring the same user experience and game quality on PCs and game consoles to mobile devices.
Graphics APIs through the years
The leading 3D API for mobile devices is based on the Khronos Group’s OpenGL ES API found in most current smartphones and tablets, across a wide range of operating systems including Android, iOS, and Windows. OpenGL ES is based on the desktop version of OpenGL optimized for mobile devices, including removing redundancy and rarely used features and adding mobile friendly data formats.
The initial version OpenGL ES 1.1 was based on fixed-function hardware and OpenGL ES 2.0 was based on programmable vertex and fragment (pixel) shaders while removing the fixed-function transformation and fragment pipeline of version 1.1. OpenGL ES 3.0 takes the industry even further by adding features based on OpenGL 3.3/4.x and reduces the need for extensions which simplifies programming by creating a tighter requirement for supported features and reduced implementation variability. Some GLES 3.0 features include occlusion queries, MRT, texture/vertex arrays, instancing, transform feedback, more programmability, OpenCL interoperability, higher quality (32-bit floats/integers), NPOT textures, 3D textures, and more.
In March 2014 at the Game Developers Conference, Khronos released OpenGL ES 3.1 with advances like compute shaders (CS), separate shader objects, indirect draw commands, enhanced texturing, and new GLSL language additions. Concurrent with the OpenGL ES 3.1 release, Google also released its Android L Extension Pack (AEP) that requires geometry (GS) and tessellation (TS) shader functionality in mobile hardware to bring advanced 3D capabilities to Android platforms to mirror PC-level graphics. Figure 3 shows a timeline of the progression of OpenGL and OpenGL ES through the years. The transitions and mapping for Microsoft’s DirectX (DX) API are shown in Figure 4. DX9 maps to OpenGL ES 2.0, and DX10/DX11 maps to OpenGL ES 3.1.
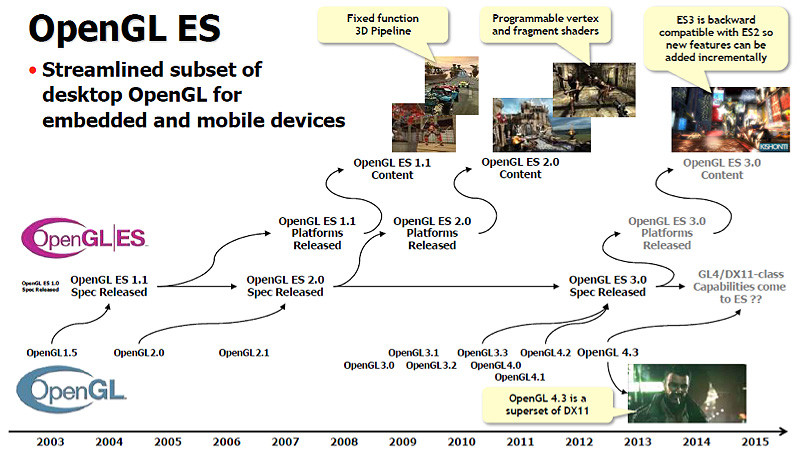
Figure 3

Figure 4
GPU goes beyond the graphics
Over the last several years, industry and university researchers found that the computational resources of modern GPUs were suitable for certain parallel computations due to the inherent parallel architecture. Calculation speed-ups shown on GPUs were quickly recognized and another segment of HPC built on the vast processing power of GPUs was born.
GPUs that go beyond graphics can be referred to as GPU compute cores or GPGPUs. Different industry standards like OpenCL, HSA, OpenVX, and Microsoft DirectCompute have come to fruition where task and instruction parallelism are now optimized to take advantage of different processing cores. In the near future, mobile devices will better take advantage of system resources by offloading the CPU, DSP, or custom cores and use the GPU to achieve the highest compute performance, calculation density, time savings, and overall system speed-up. The best approach will use a hybrid implementation where both CPUs and GPUs are tightly interleaved to hit performance and power targets.
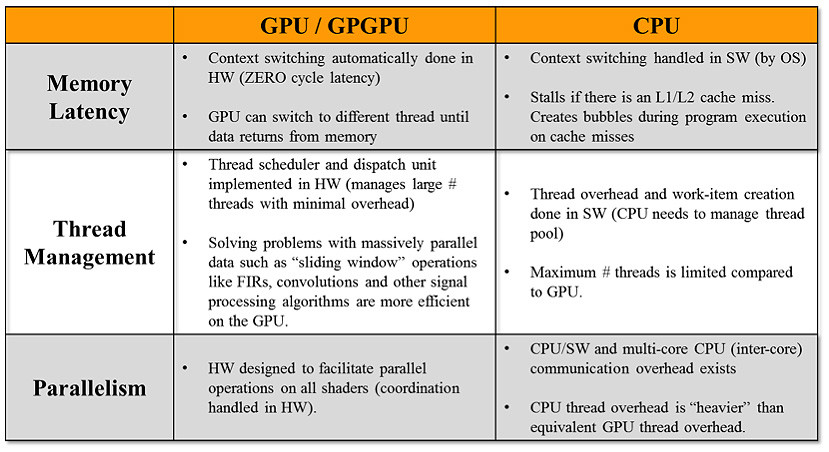
Figure 5 | The table below compares a CPU to a GPU when looking at different factors like memory latency, thread management, and execution parallelism.
Many computational problems like image processing, vision processing, analytics, mathematical calculations, and other parallel algorithms map well to the GPU SIMD architecture. You can even program the GPU to use a multi-GPU approach where a compute task and/or 3D rendering frame is split between GPUs to improve performance and throughput. The GPU can work in multi-context modes to execute 3D and compute threads simultaneously. An example would be where GPU core 1 and 2 are assigned to render images and core 3 and 4 are dedicated to GPGPU functions like particle effects (smoke/water/fire), game physics to mimic real world motion, or natural user interface (NUI) processing for gesture support. Other markets where the GPGPU is being adopted, especially in embedded/computer vision segments, include:
- Augmented reality: overlays the real world environment with GPU-generated data (images, data, 3D renderings, etc.) that can be input from various sensors, like Google Glass. AR can work with online (live and direct) or offline content streams.
- Feature extraction: vital to many vision algorithms since image “interest points” and descriptors need to be created so the GPU knows what to process. SURF (Speeded Up Robust Features) and SIFT are examples of algorithms that can be parallelized effectively on the GPU. Object recognition and sign recognition are forms of this application.
- Point cloud processing: includes feature extraction to create 3D images to detect shapes and segment objects in a cluttered image. Uses could include adding augmented reality to street view maps.
- Advanced driver assistance systems (ADAS): multiple safety features are constantly calculated in real time including line detection/lane assist (Hough Transform, Sobel/Canny algorithms), pedestrian detection (Histogram of Oriented Gradients, or HOGS), image de-warping, blind spot detection, and others.
- Security and surveillance: includes face recognition that goes through face landmark localization (Haar feature classifiers), face feature extraction and classification, and object recognition.
- Motion processing: natural user interfaces like hand-gesture recognition which separates the hand from background (like color space conversion to the HSV color space) and then performs structural analysis on the hand to process motion.
- Video processing: HEVC video co-processing using shader programs and high speed integer/floating point computations.
- Image processing: combining GPGPUs with image signal processors (ISP) for a streamlined image-processing pipeline.
- Sensor fusion: blends vision processing with other sensor data (like LIDAR) to create a 3D spatial map with depth. A similar concept used in graphics is ray tracing, where you shoot out a ray and trace its path through an image and calculate all the ray-object intersections and bounces to generate a realistic 3D image.
Consumers and industry are pushing leading edge technologies forward in the mobile space. Hence, GPU providers must constantly innovate and keep up with the latest trends, APIs, and use cases, all while maximizing performance and minimizing power and die-area increments for advanced graphics and compute features. Mobile GPU designs must be architected from the algorithm level and carefully thought out to achieve the industry’s smallest integrated design and hardware footprint. A design taken directly from a PC GPU can’t be effectively scaled down to achieve mobile power efficiency. The secret sauce lies in configuring what’s under the hood to make things click for mobile applications, without limiting functionality, robustness or required performance.
Benson Tao is a Product Technologist at Vivante Corp., responsible for product planning and business development. For over 12 years, he’s been involved in the GPU and video industry in various technical and business roles.



