
Jetson AGX Xavier for Industrial AI: Workstation Performance, Table Fan Power Consumption
December 14, 2018
Blog

NVIDIA has released the Jetson AGX Xavier module to accelerate artificial intelligence in autonomous industrial machines. This in-depth analysis of the platform explains how you can start designing.
It took years for Industrial IoT architects to conclude that data center-class performance was needed at the edge for efficient analytics, improved security, and reduced networking costs. In the world of AI and machine learning, the need for high-end processing capabilities in or near sensor devices was apparent from the start.
Consider that even simple autonomous machines (an oxymoron, I know) require massive amounts of computational power to run neural networks for functions like obstacle detection, recognition, and avoidance. Autonomous delivery vehicles produced by companies like JD and Cainiao, for example, require roughly 30 tera operations per second (TOPS) of processing performance, while self-piloting inspection drones being developed by Yamaha need about 20 TOPS.

Of course, this presents a classic design challenge for embedded and industrial engineers: balancing performance per watt. Too little performance, and the application fails. Too much power consumption, and autonomous machines must be chained to a continuous power source.
That is changing with the release of NVIDIA’s Jetson AGX Xavier module.
Server-Class Performance, Embedded Power Consumption
The Xavier SoC at the heart of Jetson AGX Xavier contains massive amounts of heterogeneous processing performance for AI-powered robotics applications, including:
- 512-core Volta GPU, with 64 TensorCores
- Octal-core, 64-bit Arm-based Carmel CPU
- Dual NVDLA (NVIDIA Deep Learning Accelerator) engines
- Dual 7-Way VLIW vision accelerator engine
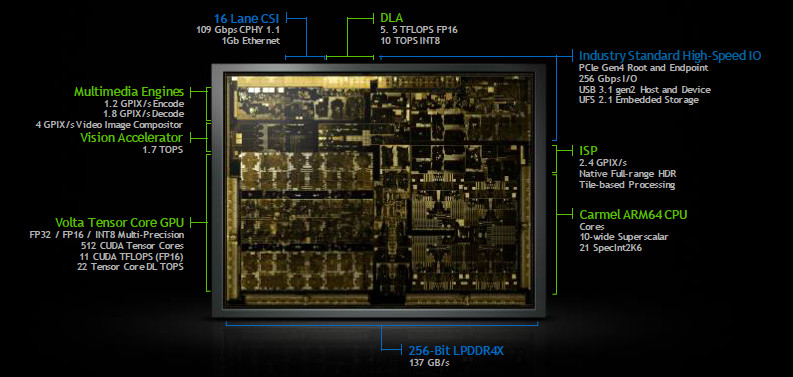
This represents up to 32 TOPS of performance in a Jetson AGX module that measures 87 mm x 100 mm. As shown in the image above, the chip also includes a 256-bit LPDDR4X interface capable of transferring data at 137 GBps to a 16 GB DRAM on the module for the frequent reads and writes associated with AI workloads.
Basically, the Jetson AGX Xavier delivers server-class performance in an embedded module form factor. Just as important, however, is that the module consumes as little of 10W, or about as much as a table fan. The operating mode is user configurable to 10W, 15W, or 30W, with NVIDIA reporting that the performance per watt (PPW) sweet spot lies around 15W. Even at that level (roughly the power consumption of a Blu-Ray player), the Jetson AGX Xavier substantially outpaces its predecessor the Jetson TX2 and an Intel Core i7 + GTX 1070 graphics in terms of inferencing performance and energy efficiency.
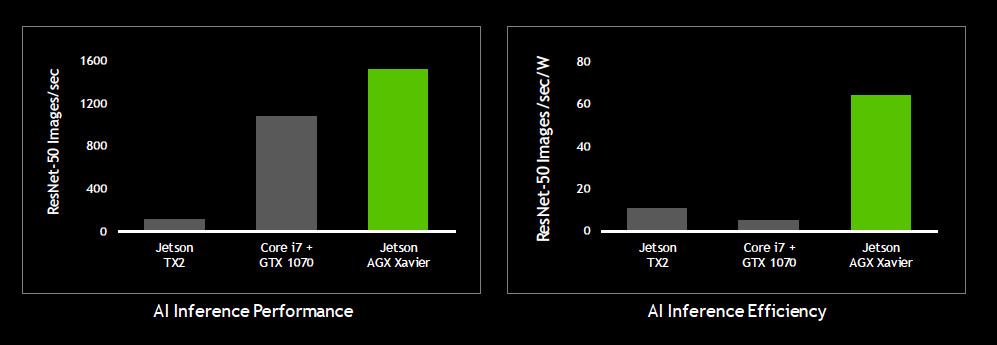
More benchmarks can be found at https://developer.nvidia.com/embedded/jetson-agx-xavier-dl-inference-benchmarks.
Jetson AGX Xavier: Under the Hood
Several features of the Jetson AGX Xavier enable this type of performance per watt, starting with the fundamental chip architecture. While each core on the SoC has its own memory, memory is zero memory copying between discrete SoC blocks. While the AGX Xavier module does provide shared memory via the external 16 GB LPDDR4X DRAM, on-chip data simply passes to the necessary processing core through the pipeline.
The heterogeneity of the architecture also drives efficiency, as workloads can be executed on the architecture best suited to the task. An example of this is the on-chip acceleration engines, which offload the Volta GPU so that it can focus on more complex or user-defined tasks. The NVDLA engines, for instance, provide up to 5 TOPS of performance when inferencing fixed-function convolutional neural networks (CNNs) at 8-bit resolution and 2.5 TFLOPS at 16-bit resolution while consuming between 0.5W and 1.5W.
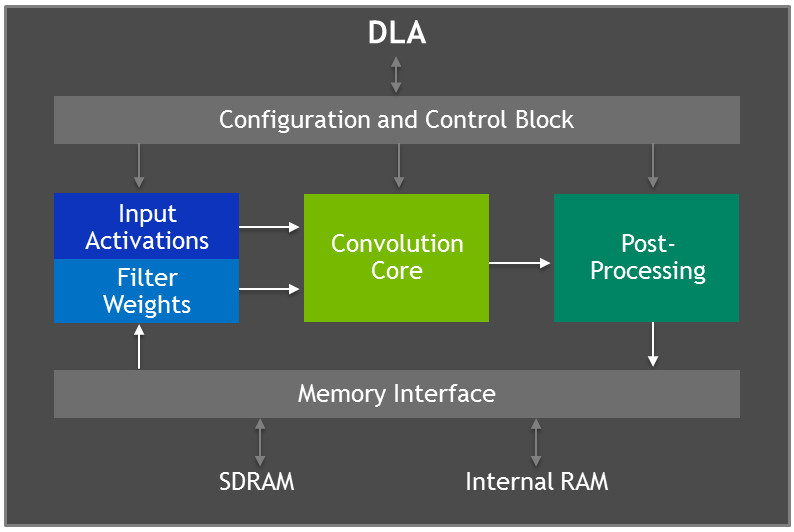
Meanwhile, the Carmel CPU core can be reserved for general-purpose computing tasks.
JetPack Simplifies Deep Learning Programming Complexity
The Jetson AGX family runs Linux, which is becoming more and more common in industrial embedded systems. What may be less familiar to many industrial and embedded developers looking to exploit the performance of the Jetson AGX Xavier is programming the GPU and/or deep learning accelerators. Fortunately, the NVIDIA JetPack 4.1.1 software development kit (SDK) provides a package of APIs, drop-in libraries, and integration with common languages in the CUDA Toolkit so that you don’t need to know how to program a GPU in order to program a GPU.
Some of the software tools in the latest JetPack release include:
- Linux For Tegra R31.0.1 (K4.9)
- CUDA Toolkit 10.0
- cuDNN 7.3
- TensorRT 5.0 GA
- OpenCV 3.3.1
- OpenGL 4.6 / GLES 3.2
- Vulkan 1.1
- Multimedia API R31.1
- Argus 0.97 Camera API
Programming the DLAs to execute neural network workloads is also simplified by APIs available in the TensorRT 5.0 package. For example, _setDeviceType() and setDefaultDeviceType() commands can be used to execute a particular neural network layer or layers on the GPU or either of the DLAs, while commands like _allowGPUFallback() lets workloads revert to the GPU if not supported by the DLAs.
In addition, Jetson AGX Xavier is supported by the DeepStream 3.0 SDK, which leverages TensorRT, CUDA, multimedia and imaging APIs to accelerate the development of video analytics applications.
Of course, low-level CUDA programming is another option.
Price, Portability, and Protracted Support
Those interested in evaluating the Jetson AGX Xavier module can get started with the NVIDIA Jetson AGX Xavier development kit, which is available to registered NVIDIA developers for $1,299. The ready-to-deploy modules are available off-the-shelf for $1,099 in 1,000-unit quantities.
That price is a tough pill to swallow for many industrial applications, even if they do need server-class performance for their autonomous machine designs. However, NVIDIA has provided a contingency plan by offering the Jetson TX2 module for $399 per unit today, and potentially less in the future (the Jetson TX1 now retails for $299 per unit from Arrow Electronics).
The Jetson TX2 is available in industrial variants with 4GB or 8GB of RAM, but more importantly, the software stack is backwards- and forwards-compatible with the entire JetPack family. At the NVDIA Developer Meetup in San Jose, Deepu Taila, VP and GM of Autonomous Machines at NVIDIA, explained that the plan was to maintain the codebase indefinitely, specifically stating that meant “for the rest of our lives.”

That’s great news for industrial and embedded developers, as it means their code can be ported to more powerful NVIDIA platforms as they come down in price, and also means that support will be available for the life of their application.
Industrial engineers, it's time to start preparing for autonomous machines.
Check out how ConnectTech is enabling industrial designs with Jetson AGX Xavier in this video interview from the 2018 NVIDIA Jetson Developer Meetup.



