
Connectivity by Design
October 27, 2021
Story
Just as the bloodstream nourishes each individual system of the human body, information and data is the lifeblood of every part of your organization. The problem is that most organizations are poorly connected. As a result, this lifeblood isn’t allowed to properly travel between systems, leaving each system isolated, underutilized, and undernourished.
Data silos are a symptom of a poorly connected system, which results in wasted time and resources and causes poor decision-making, missed opportunities, and duplication of efforts as each employee attempts to recreate existing data sets from their own, most likely outdated, cache of information.

Data is the lifeblood of your organization. (Source: Bentley Systems)
The Need for Unified and Aggregated Information
The way to address the data silo problem is to improve connectivity among these data silos and systems. Industry trends and standards such as Industry 4.0 and digital twins are the culmination of this need for unified and aggregated information to connect and curate both new and legacy data sources, creating a more holistic and better-connected ecosystem.
Connectivity by design extends and advocates not only the advance of connectivity, but also embedding connectivity into the actual design of solutions and software. Systems, by design, should be able to discover, inherit, evaluate, and share intelligence across different systems or components. We should be able to monitor, analyze, and control at the sub-unit level in real-time and visualize data at the system level and within the entire ecosystem. This is the glue that will accelerate digitalization.
Open Always Wins
Open means you are not locked into a single-vendor solution. You can import and export data freely. When you write an application with an open technology, it can run anywhere. It doesn’t have to run in any specific cloud, and it doesn’t force you to store your data in a cloud that is constrained by terms of service. You will always be able to access and export your data.
There are many advantages from which organizations can benefit when they can allow the exchange of data between multi-vendor devices without any closed or proprietary restrictions. When non-proprietary open standards are utilized, interoperability between data sources and endpoints is assured without any limitations. Peer reviews can be done easily regardless of the design platforms used so design teams can collaborate, innovate, and accelerate development at a fraction of the cost while ensuring robust and reliable data.
Openness Depends on Standardization
For most organizations, their information technology infrastructure is a hodge-podge of new, legacy, on-premises, and cloud applications and services. These systems cannot be replaced overnight and must play a role in a connected information ecosystem for years or even decades to come. Real-time information exchange among these heterogeneous and very often geographically distributed systems is critical for supporting complex business scenarios across cross-functional business processes.
Industry standards foster openness and enable interoperability between products from different vendors. They provide a basis for mutual understanding and facilitating communication, which improves inter-business communication and speeds development. Interoperability standards with staying power include:
- ISO 15926 is for data integration and interoperability in capital projects. It addresses sharing, exchange, and hand-over of data between systems.
- ISO 18101 provides guidance on the requirements for interoperability among systems of systems, individual systems (including hardware and software), and components. This standard grew out of the open standard MIMOSA CCOM.
- OPC-UA (Unified Architecture) is one of the most important communication protocols for Industry 4.0 and the Industrial Internet of Things (IIoT). It standardizes data exchange between machines, devices, and systems in the industrial environment for platform independence and interoperability.
- RAMI 4.0 is a standardized model defining a service-oriented architecture (SOA) and a protocol for network communication, data privacy, and cyber security.
Industrial standards for open interoperability enable vendors to work together to open their systems so that the users of the vendor software get a complete picture of their assets and data.
Edge or Cloud, the Best of Both Worlds – as Long as They Are Connected
When introducing IIoT to your organization, you will likely consider leveraging edge devices to collect and process the data from that device directly on the device, which drives the compute capability closer to the point of data collection (the location of the IIoT device). This is called edge computing.
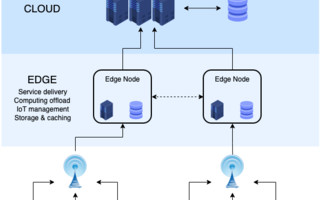
The role of edge computing is to ingest, store, filter, and send data to cloud systems. SCADA (Supervisory Control and Data Acquisition) is a control system architecture designed for remote monitoring and control of industrial applications. The difference between cloud and edge computing is simply where the processing takes place. Cloud works via a centralized data center, while the edge computing is a collection of points. There are many benefits to using cloud computing to centralize and aggregate information, which can culminate in a complete digital twin of a facility. But there are equally valid and important reasons for using edge computing, ranging from latency and bandwidth problems to cost, reliability, and privacy concerns.

Edge devices in a hyper-connected environment. (Source: Bentley Systems)
Ultimately, in a hyper-connected and open environment, in either a centralized or distributed/edge IIoT ecosystem, it is important for decision makers to get a complete, timely, accurate, and trustworthy picture of the performance of the asset, which leads to the kinds of benefits that are impossible in a data siloed ecosystem.
Moreover, while IIoT feeds have tremendous individual value, they must be connected and combined with information from traditional legacy data sources, including asset registries, work schedules, performance, failure, and reliability management plans as well as maintenance activities to optimize their value to the decision makers.
Business Outcomes and Decision-making
Business outcomes may change when injecting hyper-connectivity. For example, a team monitoring a drilling operation may want to determine when to trigger replacement of the drill head and minimize work stoppage. The camera at the tip of the drill head and associated sensors measure vibration, temperature, angular velocity, and movement, then transmit time series signals including video, audio, and other data. This data must be analyzed as close to real-time as possible with respect to object identification, precision geolocation, and process linkage.
Advanced predictive analytics compare the drill head condition to past patterns and similar rigs or geologies to determine when the drilling rate and performance will decrease below a tolerable speed and identify predictable component failures. These predictions, combined with the drilling schedule, will allow operators to decide when to replace the drill head.
Ideally the spare parts supply chain can auto-trigger based on the predictions or replacement decisions. When triggered, purchase orders are followed by transport and logistics for delivery and workforce scheduling to execute the replacement prior to breakage. Data about the drill-head and lag time for each process and operation is captured for future aggregate studies or.
In this scenario, the signals coming from the equipment need to be synthesized into an aggregated and unified set of information for optimal value. In this case, timeseries signals, asset registry data, performance data, and metrics are best evaluated together.
Clearly combining cloud computing and edge computing with engineering models, reliability analysis, supply chain and maintenance data provides the best outcome, but it is only possible in an architecture that connects data sets and data. Connected data provides context in real time, allowing you to see how asset performance is impacting key business metrics.
People, Process, and Data Connectivity
When we say “connectivity by design,” we also mean connectivity among people and between people and data. A business strategy of connectivity results in an exponential gain in productivity.
Business process integration is not just about software, and it is certainly not just about IT. Business process integration unifies the organization’s culture with an improved data analytics strategy and makes it possible for data to become actionable by people or automated in real time. Business process integration is a key business initiative that is designed to leverage connectivity.
Bentley’s iTwin Connected Data Environment

Bentley's iTwin Connected Data Environment. (Source: Bentley Systems)
In the example diagram of Bentley’s iTwin Connected Data Environment, the business processes related to the acquisition and aggregation of data are connected and collectively contribute to the creation of a real-time digital twin. In this case, the engineering models from CAD tools such as those from Bentley, AVEVA or Hexagon that implement schemas based on the ISO 15926 standard are acquired via what are called bridges. Bridges A and B, also referred to as connectors, understand these schemas and transform them to the iModel BIS schemas. From there the acquired data is aggregated to become a unified engineering dataset, which then becomes available for visualization and analytics.
Simultaneously, information from the configuration and reliability management tools is collected and transformed into an industry CCOM-compliant data model. As with the iModel, this operational data is gathered and unified into the operations data hub. There, it can be reported on and combined with engineering data and geometry data resident in the iModelHub, as well as IIoT data provided via the Microsoft Azure IoT hub, to provide the user with a complete and real-time digital twin.
A digital twin is a digital representation of a physical asset, process, or system, which allows us to understand and model its performance. Digital twins are continuously updated with data from multiple sources, which allow them to reflect the current state of real-world systems or assets. Everything is connected to everything and the ability to use this information to support decision-making is where the true value of a digital twin is realized.
Why Open, Why Connected, Why Now?
Everybody says “open.” But there aren’t degrees of openness—either you mean it or you don't. Open technology is designed to have vendor-switching capability. Adopting and natively embedding patterns such as open-source and open-interoperability standards such as ISO 15926 and more recently ISO 18181 makes it as easy as possible for customers and third-party developers to interact with applications and cloud services.
Open source and open data pave the way to creating a complete and high-fidelity digital twin that fully represents a facility in all aspects from design, construction, commissioning, maintenance, and operations.
Open and connected isn’t a goal in and of itself. It is a corporate strategy that is built into the fabric of an organization that enables users of the technology to have easy access to their data.

With more than 20 years experience in the fields of software engineering, product and solutions architecture and more than 15 years in the disciplines of design change management, configuration management and document management, Hilmar designed, architected and led highly competent teams in developing and deploying software designed to solve complex problems around engineering and operations processes.



