
Designing high-quality acoustic audio for IoT applications
February 08, 2018
Product

As MCUs are at core of all IoT audio systems, it is important to select an MCU that integrates the necessary audio technology required to design a reliable noise-free audio system.
Audio is an integral part of many IoT applications, including consumer goods like speakers and headphones, wearables and medical equipment like hearing aids, automation and industrial control applications, entertainment systems, and automotive infotainment units, to name a few.
IoT audio can be broadly classified into three categories: streaming media (i.e., music, voice, and data), voice recognition/command, and wireless connected by Bluetooth and Wi-Fi (for example, streaming multi-channel audio over Wi-Fi to a home surround system). However, designing a high-quality, uninterrupted acoustic audio subsystem can be a challenge when engineers must adhere to the stringent constraints required by IoT-based devices.
Further complicating design is the need to include advanced features such as speech recognition that allow, for example, a driver to control the infotainment system in a car with the same hands-free ease as a cell phone. As MCUs are at core of all these audio systems, it is important to select an MCU that integrates the necessary audio technology required to design a reliable noise-free audio system. This article explores the audio technologies available to design such systems.
Components of an audio subsystem
Audio for IoT involves three primary activities: steaming high-quality voice/data, wireless transmission, and voice recombination controls. Figure 1 shows the most important building blocks of an embedded system.
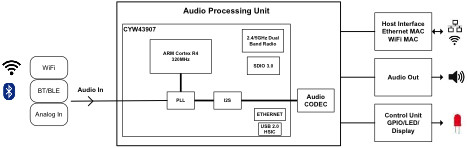
Note that many of these functions can be integrated in a modern MCU such as, as is used in this example, the Cypress CYW43907 with integrated Wi-Fi 802.11n. Some of the important audio technologies an IoT-based system may include are:
Music applications
An audio-enabled MCU allow engineers to decode the MP3/4 streams that are used by most popular media players and content providers. Many designs also need to support WMA and Apple’s AAC decoding, which require more processing power. It is often possible to utilize a low-cost audio MCU in consumer audio applications, usually by managing the digital music streams in audio accessories, such as digital speaker sets.
In these applications, a frame of PCM audio data (encapsulated in the USB audio class format) arrives every 1 ms via one of the processor’s SPI/I²C serial channels. Depending on the source, the audio stream may arrive in one of several formats (i.e., left-justified, right-justified, I2S, etc.) However, some lower-cost codecs can only accept a specific format. In these cases, the MCU plays a major role in ensuring that the data is properly aligned before it is fed to the codec.
Since not all audio sources use the same sampling rate, the codec must also adapt its sampling frequency to the source or rely on the MCU to convert the sampled data stream into a common data rate (see Figure 2). In these cases, the MCU must manage the stream to avoid under or over-run conditions that would otherwise cause silences, pops, and audio discontinuities that occur with data loss and disrupt the user listening experience. Note that an audio MCU can also be used to implement other capabilities of the audio subsystem, such as controlling the lighting during audio playback.
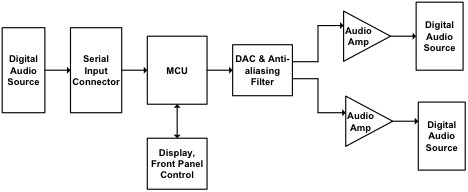
To enable audio in a wide range of applications, the audio MCU needs to support a variety of audio technologies. Figure 3 shows examples of these audio technologies.
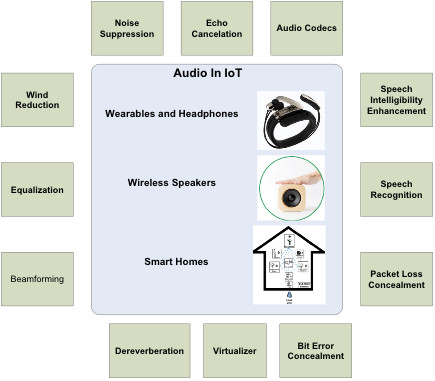
Audio codec (enCOder/DECoder)
The audio codec is the main front-end component of an audio system. Many MCUs architected for IoT applications support codec functionality in hardware. This allows the system to reduce the size of digital audio samples to both speed up wireless transmissions (saving power) and conserve storage space (reducing the strain on internal memory capacity). A codec may support a variety of audio standard formats, such AAC, AC-3, and ALAC. To do so, it will need a decode access unit (AU) which is implemented before any audio post-processing (e.g. DSOLA, SOLA). When used with the standard audio formats like AAC, AC-3 and ALAC, audio is categorized in such a way that subsequent audio samples are within the prescribed format as specified in the data stream of audio packet. The packet interval is also managed to allow for minimal cross jitter and uninterrupted operation in the presence of congestion. The AU payload size allows for any concealment that needs to be performed.
Baseband processing
The baseband signal is a fundamental group of frequencies in an analog or digital waveform that can be processed by an electronic circuit. Baseband signals can be composed of a single frequency or group of frequencies or, if in the digital domain, of a data stream sent over a non-multiplexed channel. The baseband is defined as the mixing of a baseband (signal/s) with a carrier signal to result in a modulated signal. Note that in MCUs supporting IoT audio, the audio codec is integrated with baseband processing and RF on a single chip. The audio codec may be implemented in a variety of wireless transceivers to offer voice data and/or music functions. The codec also has monaural and stereo channels for audio output, as well as stereo inputs.
Packet loss concealment and data replication
Excessive delay, packet loss, and high delay jitter all impair communication quality. The possibility of burst packet losses increases with network loading and results in interruptions that can be heard by users. Robust audio transmission over Wi-Fi can be enhanced through advanced capabilities like Cypress’ Packet Loss Concealment technology. The system architecture source/Sink is as follows: one source captures audio, muxes the PCM data over an RTP stream structure, and synchronizes the clock with all the sinks connected to the PLC Source.
Note that the performance of the communication link depends on the quality of the link budget performance. This link budget is determined by three factors: transmit power, transmitting antenna gain, and receiving antenna gain. For example, if the power minus free space loss of the link path is greater than the minimum received signal level of the receiving radio, then it is possible to make a reliable communication over the 802.11 network (see Figure 4).
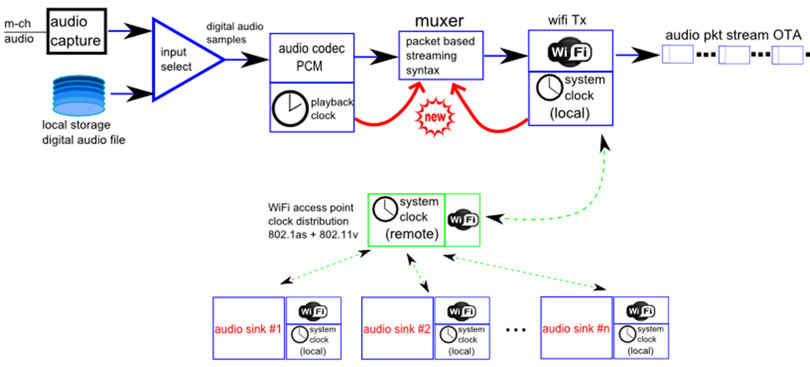
Speech intelligibility enhancement (SIE)
Background noise in an audio system reduces the intelligibility of speech. If the noise is beyond certain level, then speech can become difficult for users to understand. The availability of real-time continuous speech recognition on embedded devices requires the system to be able to enhance intelligibility in noise-corrupted speech. Selecting an MCU that supports porting and optimization of popular large vocabulary continuous speech recognition (LVCSR) systems can simplify development.
Wake-up phrase detection (WUPD)
This advanced feature enables user to turn on systems in a hands-free manner by activating devices by voice (see Figure 5).
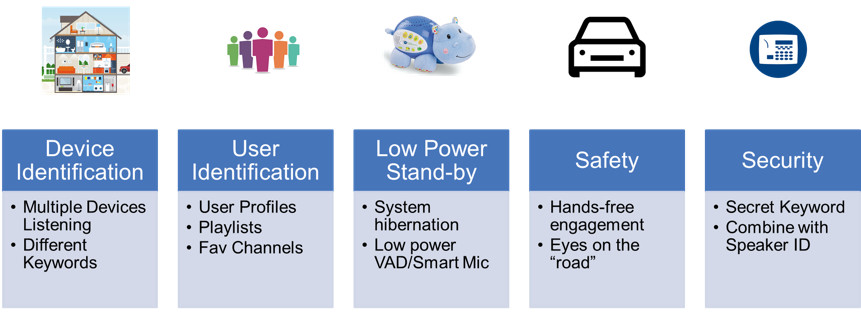
Efficient multicasting to one or more speakers
Multicasting is a network addressing method for delivering information to a group of destinations simultaneously using the most efficient strategy. Messages are delivered over each link of the network only once, creating copies only when the next link splits to multiple destinations (typically at network switches and routers). However, like the User Datagram Protocol (UDP), multicast does not guarantee the delivery of a message stream, resulting in dropped messages or messages delivered out of order. Reliable Multicasting (RMC) provides acknowledgement for multicast data packets (data packets only) so that some specific multicasting data packets can be reliably delivered. The transmitter chooses the receiver with the weakest RSSI to acknowledge frames. In an IoT context, implementing RMC means the Wi-Fi transmitter chooses one of the many Wi-Fi receivers to acknowledge frame reception. The transmitter chooses the receiver with the weakest RSSI to acknowledge frames. The implementation uses an action frame containing a proprietary RMC information element to inform and enable the acknowledger. The implementation also contains RMC-specific Wi-Fi driver commands to set the multicast MAC address and to enable and disable RMC.
Time synchronization requirements are met for audio and video where the transmission delays are fixed and symmetrical; for example, RMC can rely on highly accurate timing and synchronization for smooth cell-to-cell transfers of voice, video, and mobile data. Achieving highly-accurate and precise timing is not a simple feat from a technology perspective, so it is important to find an implementation that you can verify meets your application requirements.
Framing formats, forward error correction, and packet replication
For audio streaming, it is critical that the clock be in synch with all the Wi-Fi receivers. One approach is to use a common clock for the source and receiver devices, often referred to as a wall clock or System Time Clock (STC). First, each sink (receiver) synchronizes its STC (wall clock) with the source/transmitter’s STC (master wall clock). Each sink can now recover the clock of the transmitter since the timestamp (available in the extension header of each RTP packet) inserted by the source reflects the sampling instant of the media relative to the common clock.
The STC is based on the Grandmaster clock value as outlined in the 802.1AS specification. Since the correlation between the STC and the source device’s media clock (as it related to the RTP or media timestamp) is known by all sink devices, each sink can reconstruct a copy of the source device’s RTP media clock and queue its output appropriately for proper rendering. A transparent clock is one where the hardware/ucode can time stamp receive and transmit packets as close to the MAC/PHY interface as possible. Although this clock value is not used for playback, it may be used to measure the jitter through the system and conduct a thorough performance analysis.
Smart home audio system example
To understand IoT audio in context, consider the example of a smart home and the role audio can play in improving the overall capabilities of the smart home system. A home becomes a smart home when devices and appliances within the home can communicate with each other and the people living there. By increasing our interconnectedness, smart homes are improving our quality of life, as well as increasing our security. Figure 6 shows an example of a smart home.
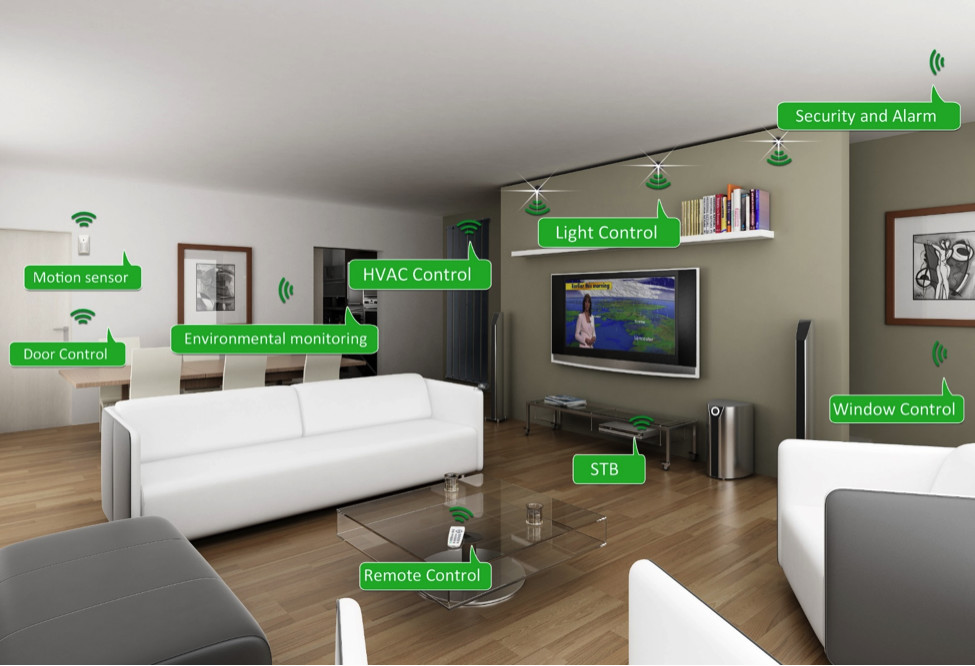
One of the primary use cases for audio in a smart home is to store and share audio over Wi-Fi or Bluetooth. The choice of Wi-Fi over BLE varies from application to application and depends on range and audio quality requirements. For example, if someone at the door rings the doorbell, instead of it only chiming in one place in the home, the home controller can play a specific sound in every room of the house. Similarly, the controller could restrict the sound to the specific rooms, such as not in the baby’s nursery. An embedded controller helps in processing this audio and makes the system more intelligent by managing various output control functions.
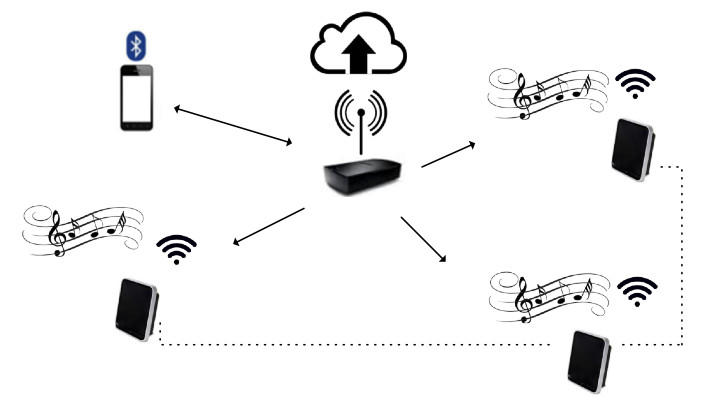
Figure 7 shows a wireless audio speaker system as might be found in a smart home. This audio system can improve the quality of the audio experience in several different ways:
Rebroadcast audio system
The rebroadcast audio system has become a significant application in the audio market. A wireless audio rebroadcast system is the centerpiece of a smart home, bringing together the many different smart devices in the home and making intelligent decisions on behalf of the user. For example, the audio system can control lighting patterns in the house based on the music currently being played. It could also use text-to-speech recognition to read user notifications or emails aloud. Users also have the option to create zones within a multi-room audio system by using networkable audio devices such as wireless speakers incorporated in different rooms of the house. This approach creates an entire ecosystem to ensure a home always runs at maximum efficiency while minimizing interaction with the people living there. To create such an ecosystem, IoT designers need to select an embedded microcontroller with the right level of performance and audio-based features that have been optimized for IoT applications.
Digital signal processing effects
Audio signal processing in the digital domain is an essential part of any audio system before audio data is transmitted over a wireless link. Such processing typical involves measuring, filtering, and/or compressing audio analog signals. An embedded MCU with integrated DSP capabilities enables effects such as adding a digital mixer and supporting remote control functions. With a 5-band EQ on every channel, audio playback can integrate neatly with the majority of sequencer applications to form a powerful studio system.
Live audio streaming
Music streaming services such as Spotify and Pandora allow users to choose the songs they want to play. Ideal use of these services enables users to stream audio inside home with support for some smart voice commands, such as selecting which songs to add to a playlist. They also enable live Internet streaming to the different rooms of the home using the smart home audio system.
Audio is an important capability in many IoT systems, and high-quality audio is needed to support many advanced features, such as streaming quality audio, voice recognition/command, and audio transmission over wireless link (Bluetooth and Wi-Fi) using a smart home audio system. With the right MCU and integrated technology, it is possible to design a reliable, noise-free, and cost-effective IoT audio system.
References:
- CYW43907 - WICED IEEE 802.11 a/b/g/n SoC with an Embedded Applications Processor
- WICED Software
- WICED CYW43907 Evaluation Kit
- PSoC 6: PURPOSE-BUILT FOR THE IoT



