
Neural Network Optimization with Sparse Computing and Facebook Glow
September 28, 2018
Story

There are 27 different types of neural networks. The number of neural network types has increased as engineers and data scientists seek out optimized implementations of AI for use cases.
“The Mostly Complete Chart of Neural Networks, Explained” was published in August 2017, and identified 27 different types of neural networks. The number of neural network types has increased since then as engineers and data scientists seek out optimized implementations of artificial intelligence (AI) for their use cases.
Processor architects have been scrambling to deliver novel compute platforms capable of executing these workloads, but efforts are also being made in software to improve the efficiency of neural networks. One such technique is pruning, or the removal of duplicate neurons and redundancies from a neural network to make it smaller and faster (Figure 1).
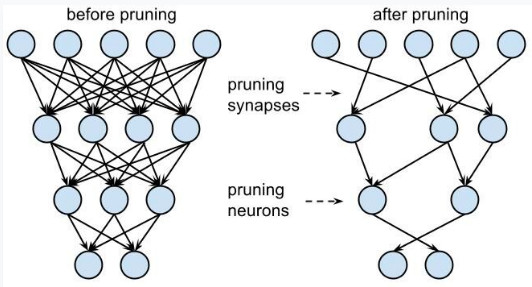
Pruning in general is an important enabler for deep learning on embedded systems, as it lowers the amount of computation required to achieve the same level of accuracy. Pruning techniques can also be taken a step further to minimize specific inefficiencies of neural networks, such as sparsity.
Sparsing through Neural Networks
In a neural network graph, sparsity refers to neurons that contain a zero value or no connection to adjacent neurons (Figure 2). This is an inherent characteristic of the hidden matrices that exist between the input and output layers of a deep neural network, as a given input typically activates fewer and fewer neurons as data passes through the graph. The fewer connections in the neural network matrix, the higher the sparsity.
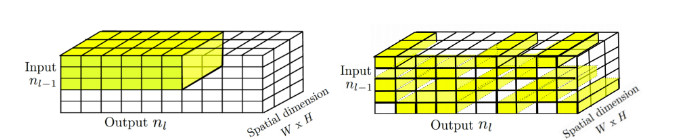
“As you go through these layers and multiply a 1 with a 0 you get a 0, so the sparsity in the activation of neurons increases as you progress through layers,” says Lazaar Louis, Senior Director and Head of Marketing and Business Development for Tensilica products at Cadence Design Systems. “On average, current neural networks exhibit 50 percent sparsity in activation from input to output.”
Rather than using processor and memory resources to compute zero values of a sparse neural network, pruning the network to induce sparsity can be turned into a computational advantage. Pruning for sparsity can be achieved by forcing near-zero values to absolute zero, which, along with model retraining, can increase sparsity to 70 percent.
Once a neural network has been pruned for increased sparsity, compute technologies such as Cadence’s Tensilica DNA 100 Processor IP can take advantage by only performing multiply-accumulate (MAC) operations against non-zero values (Figure 3). This is possible thanks to an integrated sparse compute engine, which includes a direct memory access (DMA) subsystem that reads values before passing executables along to the processing unit.
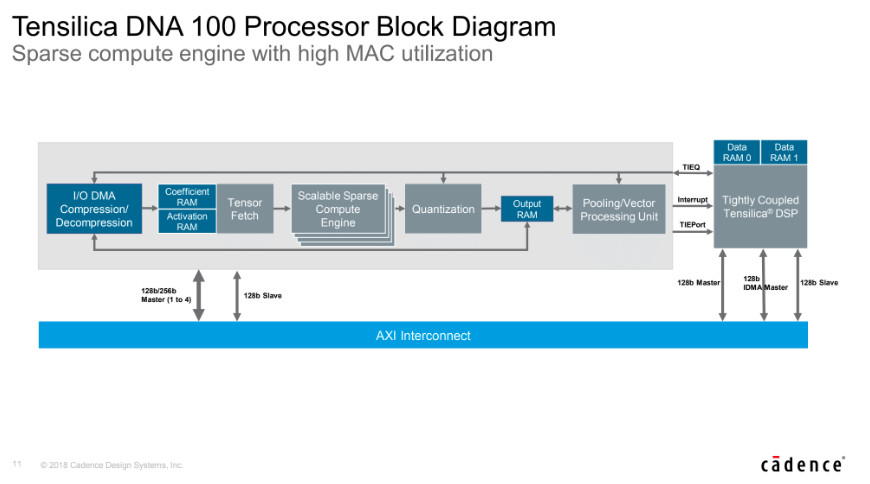
Overall, this provides higher MAC utilization for DNA 100 IP that results in a 4.7x performance increase over alternative solutions with similar array sizes.
Glowing Compilation
Like any embedded processor, the DNA 100 leverages a compiler to help it interpret the sparsity of neural network graphs. The Tensilica Neural Network Compiler takes floating point outputs from deep learning development frameworks such as Caffe, TensorFlow, TensorFlow Lite, and the Android Neural Network (ANN) app, and quantizes them into integers and machine code optimized for Cadence IP.
The compiler also assists with pushing near-zero weights to zero and, where possible, fusing multiple neural network layers into individual operations. These capabilities are critical to improving neural network throughput on devices like the DNA 100 while also maintaining accuracy within 1 percent of the original floating point model.
Despite the advantages of the Tensilica Neural Network Compiler, however, engineers are already challenged by a growing number of neural network types, deep learning development frameworks, and AI processor architectures. As this trend continues, developers will seek compilers that enable them to use the widest selection of neural network types and tools on the most diverse range of processor targets. Vendors like Cadence, on the other hand, will require solutions that allow them to support the evolution of technologies further up the stack.
Realizing the market need, Facebook has developed Glow, a graph lowering machine learning compiler for heterogeneous hardware architectures based heavily on the LLVM compiler infrastructure. The objective of Glow is to accept computation graphs from frameworks like PyTorch and generate highly optimized code for multiple hardware targets using math-related optimizations. It does so by lowering neural network dataflow graphs into an intermediate representation and then applying a two-phase process (Figure 4).

The first phase of Glow’s intermediate representation allows the compiler to perform domain-specific improvements and optimize high-level constructs based on the contents of the neural network dataflow graph. At this stage, the compiler is target-independent.
In the second phase of the Glow representation, the compiler optimizes instruction scheduling and memory allocation before generating hardware-specific code. Because of its incremental lowering phase and the fact that it supports a large number of input operators, the Glow compiler is able to take advantage of specialized hardware features without implementing all of the operators on every supported hardware target. This not only reduces the amount of memory space required, but also makes it extensible for new compute architectures that only focus on a few linear algebraic primitives.
Esperanto Technologies, Intel, Marvell, Qualcomm, and Cadence have already committed to Glow in future silicon solutions
“Facebook Glow allows us to quickly optimize for technologies that are yet to come,” Louis says. “Let’s say there’s a new network that's introduced. Either somebody will contribute that, or we will do it. They want to enable an open source community, so people can come in and contribute and accelerate things that are generic.
“They’ve also introduced the capability in Glow to plug various accelerators in, so we can make it fit our architecture,” Louis continues. We see Glow as the underlying engine in our compiler [moving forward].”
Embedded Neural Networking: Less is More
The hype, research, and development around AI has exploded over the last couple of years, but, as often is the case with embedded technology, less is proving to be more.
Pruning neural networks is quickly becoming a common practice for neural network developers as they attempt to improve performance without sacrificing accuracy. Meanwhile, Facebook Glow is addressing processor fragmentation before it can deter AI adoption.
Using the one right tool extremely well usually leads to success. For neural networks, using the Glow compiler and sparse computing techniques could be what gets the job done.



