MLPerf: The New Industry Benchmark for AI Inferencing at the Edge
November 27, 2019
Blog

TOPS. FLOPS. GFLOPS. AI processor vendors calculate the maximum inferencing performance of their architectures in a variety of ways. Do these numbers even matter?
TOPS. FLOPS. GFLOPS. AI processor vendors calculate the maximum inferencing performance of their architectures in a variety of ways.
Do these numbers even matter? Most of them are produced in laboratory-type settings, where ideal conditions and workloads allow the device under test (SUT) to generate the highest scores possible for marketing purposes. Most engineers, on the other hand, could care less about these theoretical possibilities. They are more concerned with how a technology impacts the accuracy, throughput, and/or latency of their inference device.
Industry-standard benchmarks that compare compute elements against specific workloads are far more useful. For example, an image classification engineer could identify multiple options that meet their performance requirements, then whittle them down based on power consumption, cost, etc. Voice recognition designers could use benchmark results to analyze various processor and memory combinations, then decide whether to synthesize speech locally or in the cloud.
But the rapid introduction of AI and ML models, development frameworks, and tools complicates such comparisons. As shown in Figure 1, a growing number of options in the AI technology stack also means an exponential increase in permutations that can be used to judge inferencing performance. And that’s before considering all the ways that models and algorithms can be optimized for a given system architecture.

Needless to say, developing such a comprehensive benchmark is beyond the ability or desire most companies. And even if one was capable of accomplishing this feat, would the engineering community really accept it as a “standard benchmark?”
MLPerf: Better Benchmarks for AI Inference
More broadly, industry and academia have developed several inferencing benchmarks over the past few years, but they tend to focus on more niche areas of the nascent AI market. Some examples include EEMBC’s MLMark for embedded image classification and object detection, the AI Benchmark from ETH Zurich that targets computer vision on Android smartphones, and Harvard’s Fathom benchmark that emphasizes the throughput of various neural networks but not accuracy.
A more complete assessment of the AI inferencing landscape can be found in MLPerf’s recently-released Inference v0.5 benchmark. MLPerf Inference is a community-developed test suite that can be used to measure the inferencing performance of AI hardware, software, systems, and services. It is the result of a collaboration between more than 200 engineers from more than 30 companies.
As you would expect from any benchmark, MLPerf Inference defines a suite of standardized workloads organized into “tasks” for image classification, object detection, and machine translation use cases. Each task is comprised of AI models and data sets that are relevant to the function being performed, with the image classification task supporting ResNet-50 and MobileNet-v1 models, the object detection task leveraging SSD models with ResNet34 or MobileNet-v1 backbones, and the machine translation task using the GNMT model.
Beyond these tasks is where MLPerf Inference starts to deviate from the norm of traditional benchmarks. Because the importance of accuracy, latency, throughput, and cost are weighted differently for different use cases, MLPerf Inference accounts for tradeoffs by grading inferencing performance against quality targets in the four key application areas of mobile devices, autonomous vehicles, robotics, and cloud.
To effectively grade tasks in a context that is as close as possible to a real-world system operating in these application areas, MLPerf Inference introduces a Load Generator tool that produces query traffic based on four different scenarios:
- Continuous single-stream queries with a sample size of one, common in mobile devices
- Continuous multi-stream queries with multiple samples per stream, as would be found in an autonomous vehicle where latency is critical
- Server queries where requests arrive at random, such as in web services where latency is also important
- Offline queries where batch processing is performed and throughput is a prominent consideration
The Load Generator delivers these scenarios in modes that test for both accuracy and throughput (performance). Figure 2 depicts how a SUT receives requests from the Load Generator, accordingly loads samples from a data set into memory, runs the benchmark and returns the results to the Load Generator. An accuracy script then verifies the results.
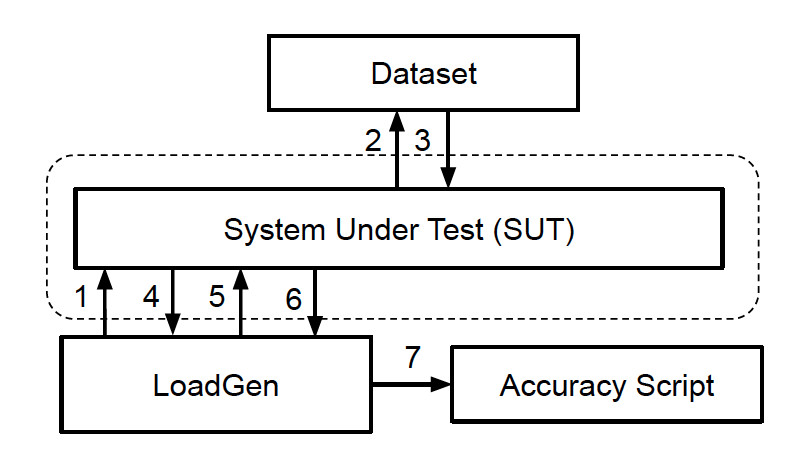
As part of the benchmark, each SUT must execute a minimum number of queries to ensure statistical confidence.
Furthering Flexibility
As mentioned earlier, the variety of frameworks and tools being used in the AI technology marketplace are a key challenge for any inferencing benchmark. Another consideration mentioned previously is the tuning of models and algorithms to squeeze the highest accuracy, throughput, or lowest latency out of an AI inferencing system. In terms of the latter, techniques like quantization and image reshaping are now common practice.
MLPerf Inference is a semantic-level benchmark, which means that, while the benchmark presents a specific workload (or set of workloads) and general rules for executing it, the actual implementation is up to the company performing the benchmark. A company can optimize the provided reference models, use their desired toolchain, and run the benchmark on a hardware target of their choosing so long as they stay within certain guidelines.
It's important to note, however, that this does not mean that submitting companies can take any and all liberties with MLPerf models or data sets and still qualify for the primary benchmark. The MLPerf Inference benchmark is split into two divisions – closed and open – with the closed division having more strict requirements as to what types of optimization techniques can be used and others that are prohibited.
To qualify for the closed division, submitters must use the provided models and data sets, though quantization is permitted. To ensure compatibility, entrants in the closed division cannot utilize retrained or pruned models, nor can they use caching or networks that have been tweaked to be benchmark- or data set-aware.
The open division, on the other hand, is intended to foster innovation in AI models and algorithms. Submissions to the open division are still required to perform the same tasks, but can change the model type, retrain and prune their models, use caching, and so on.
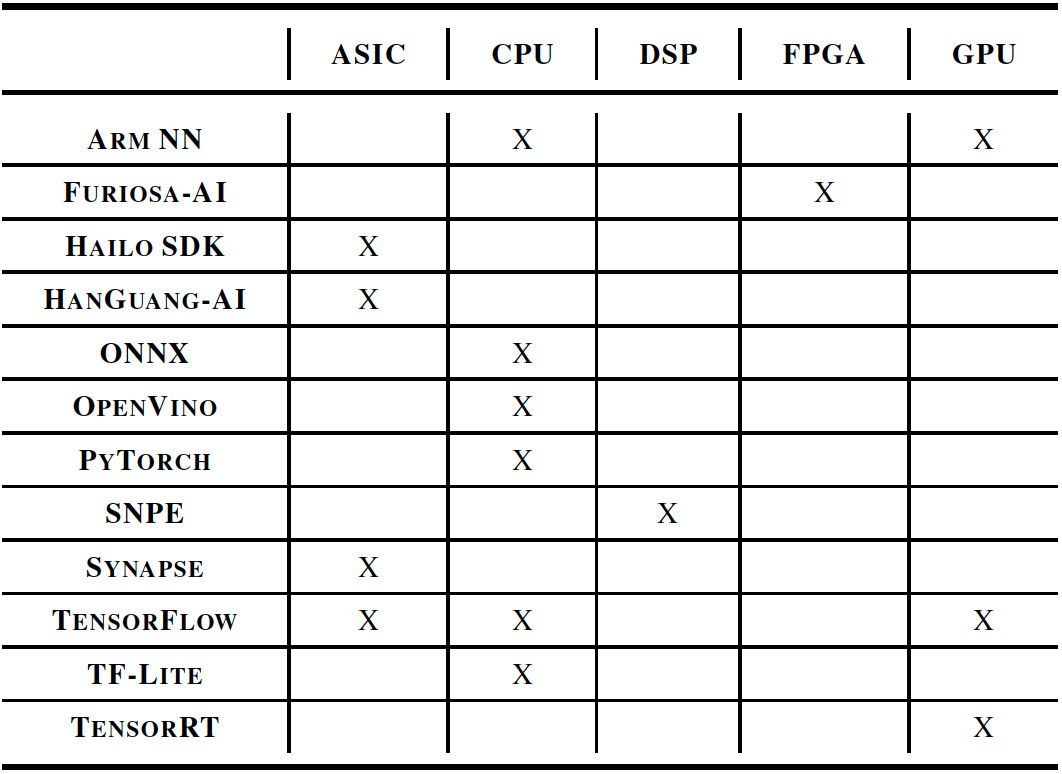
As restrictive as the closed division might sound, more than 150 entries successfully qualified for the MLPerf Inference v0.5 launch. Figures 3 and 4 demonstrate the diversity of AI technology stacks used by the entrants, which spanned almost every kind of processor architecture and software frameworks ranging from ONNX and PyTorch to TensorFlow, OpenVINO, and Arm NN.

Take the Guesswork Out of Evaluation
While the initial release of MLPerf Inference contains a limited set of models and use cases, the benchmarking suite was architected in a modular, scalable fashion. This will allow MLPerf to expand tasks, models, and application areas as technology and the industry evolve, and the organization already plans to do so.
The latest AI inferencing benchmark is obviously significant as the closest measure of real-world AI inferencing performance currently available. But as it matures and attracts more submissions, it will also serve as a barometer of technology stacks that are being deployed successfully and a proving ground for new implementations.
Rather than crunching vendor-specific datasheet numbers, why not let the technology speak for itself? After all, less guesswork means more robust solutions and faster time to market.
For more information on MLPerf Inference, visit https://edge.seas.harvard.edu/files/edge/files/mlperf_inference.pdf.