Secure Flash for Machine Learning on Edge Devices
April 15, 2020
Story

Initially, cloud computing with all of its ?limitless? capabilities seemed to eliminate the need for edge devices to have any substantial intelligence.
Initially, cloud computing with all of its “limitless” capabilities seemed to eliminate the need for edge devices to have any substantial intelligence. However, there has been a trend in the past few years to implement Artificial Intelligent (AI) and Machine Learning (ML) in edge devices to address issues like data transmission latency, privacy, and greater device autonomy. This brings certain memory requirements for building the embedded systems in the edge devices. This article explores certain ML schemes that are suitable for edge devices and the non-volatile memory requirements making them possible.
Why Machine Learning (ML) on edge devices
Edge devices are where ML data is generated. Applications in IoT, industrial, and consumer segments generate huge amount of data from their own sensors and need to be able to make fast decisions based on commands from Human-Machine Interfaces (HMI). Sensor fusion technology makes obtaining data on edge devices easier, faster, and more accurate. HMIs make human interactions more user friendly and adaptive. Naturally, it makes sense to process data in the ML computing engine closer to their origin. Edge computing will never replace cloud computing; however, not having to transmit data to the cloud, the machine can be trained quicker and the connection bandwidth to the cloud server can be greatly reduced.
A wide range of IoT applications can benefit from having local AI processing available. Figure 1 shows a diagram from SensiML that lists examples for AI processing on edge devices.

Figure 1: Example applications that can benefit from local AI processing (source: SensiML)
Of course, implementing ML on edge devices certainly have challenges. For example, edge devices may rely on batteries, and thus have limited energy budget. They may also have limited computing capacity and/or memory space. However, modern MCU technologies are making this possible on edge devices. As shown in Figure 2, from the study done by Barth Development, for the last couple decades, we can see that while MCU power consumption stay relatively flat, the number of transistors, clock speed, number of parallel cores, are all trending up. As more high-performance, low-power MCUs become available, edge computing can help build an intelligent and user-friendly system.

Figure 2: MCU Study in past years (source: Barth Development)
Different Schemes of Machine Learning
In general, ML can be divided into two main categories: Supervised Learning and Unsupervised Learning. Supervised Learning refers to training the machine using data that are “labeled”, meaning each data sample contains the features and the answer. By feeding the machine these labeled data, we are training it to find correlations between the features and the answer. After training, when we feed the machine a new set of features, hopefully it will come up with the correct answer that we are expecting. For example, a device may be trained to find text and numbers in an image captured by its video source (i.e., a camera). To describe the process in a very simplified way, the device is trained by being given images that may or may not contain text and numbers, along with the correct answer (i.e. “the label”). After training, the device is equipped to find text and numbers in any given new images.
Unsupervised Learning, on the other hand, refers to an approach where the machine is fed data that are not “labeled”, meaning that there is no answer for each set of features. The goal of unsupervised learning is to find hidden information from all these data, whether to clusterize the data sets, or find associations among them. An example of Unsupervised Learning may be to perform quality control at the end of the production line, finding an abnormal product from all other products (i.e. Anomaly Detection). The device is not given “labeled” answers to indicate which products are abnormal. By analyzing features in each product, the algorithm automatically identifies bad products from among the majority of good products, as the device is trained to see the differences between them.
In this article, we will attempt to go a little bit deeper into Supervised Learning algorithm that can be deployed in edge devices. We will use some simple mathematic formulas in order to explain the differences between two learning algorithms.
As stated above, Supervised Learning feeds labeled data sets into the device being trained. Suppose each data set contains a number of features x1, x2 … xn. Next, assign a coefficient q to each feature, and write down the function. This is called the hypothesis function, hq(x):
hq(x) = q0 + q1 x1 + q2 x2 + q3 x3 … + qn xn
Training the machine means an appropriate set of q (q0, q1, q2, …, qn) is found so that the hypothesis output hq(x) is as close to the given answers (labels) as possible. After training, when a new set of feature X (x1, x2, …, xn) is presented, the hypothesis function will give an output that is based on the optimal set of q.
One method to find q is to use linear regression with gradient descent. The following steps are a simplified description of this method:
1.Choose an initial set of …n. Then calculate the difference between the hypothesis and the given answer Y. This difference is often called the cost.
2.Keep changing towards the direction of smaller cost. Recalculate the cost each time. This step is repeated until the cost is no longer reducing.
3.If the cost is no longer reducing, we have reached an optimal set of that gives us a minimum cost for all the given samples.
4.Now this set of can be used to predict the output if a new set of X is given.
The name gradient descent comes from the method of changing q in Step 2. By updating q in the direction of the gradient, the algorithm guarantees it will converge to an optimal value. Figure 3 shows a graphical representation of gradient descent to get to the minimum cost function J(q0, q1).
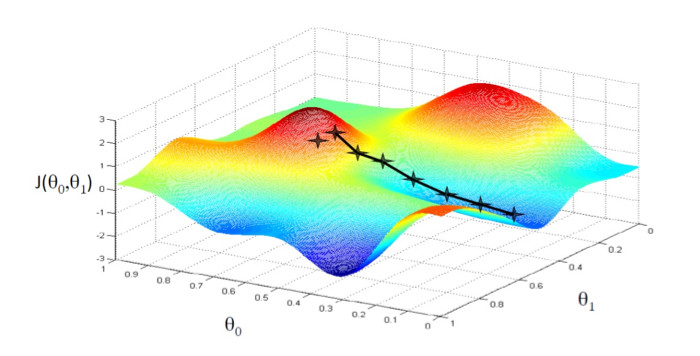
Figure 3: Cost Function J vs Parameter set q in Gradient Descent
If the calculation of the cost in Step 2 is done over all given data samples, the method is called Batch Gradient Descent. At each update of q, the algorithm calculates the cost over all training data samples. This way of calculation gives better direction how to change q. However, if the given training data sample set is huge, calculating the cost over all samples requires extensive calculating power. Moreover, the system must store all data samples during training.
A different approach for gradient descent is to execute Step 2 over a subset of data samples. This approach is called Stochastic Gradient Descent. The algorithm changes q based on a smaller set of data samples at each iteration. This method may take more iterations to reach optimal q, but it saves substantial computing power and potentially time because it does not need to calculate the cost over the entire set of data samples.
Using the Stochastic Gradient Descent method, the smallest number of samples used for calculating the cost is one. If the ML algorithm refines q as a new data sample is available, we can view this ML algorithm as a continuing behavior updating based on sequential data samples. As each available data sample comes in, the algorithm calculates the new q. As a result, the system updates the hypothesis function dynamically at each step. This method is also called Online Gradient Descent or Online Machine Learning.
Batch Gradient Descent vs Online Machine Learning
Between Batch Gradient Descent and Online Machine Learning, the latter has certain characteristics that are suitable on edge devices.
1.Unlimited data samples
As mentioned before, edge devices are usually equipped with sensors or an HMI that can continuously provide endless data samples or human feedback. Therefore, an Online ML algorithm can continuously learn from the data changes and improve the hypothesis.
2.Computing Power
Edge devices typical have limited computing power. It may not be practical to run a Batch Gradient Descent algorithm for huge data samples. However, by computing one data sample at a time, as in Online ML, the MCU doesn’t have to have huge computing power.
3.Non-Volatile (NV) Memory
A Batch Gradient Descent algorithm requires the system to store the whole training set, which must reside in non-volatile storage, while an Online ML algorithm computes incoming data sample one at a time. An Online ML algorithm may discard data or store only small set of samples to conserve non-volatile storage. That is particularly suitable for edge devices where non-volatile memory may be limited.
4.Adaptability
Imagine an Online ML algorithm performing speech recognition on an edge device. By continuously training the algorithm through new data samples, the system can dynamically adapt to a specific user and/or accent.
Non-Volatile Memory Requirements for ML on Edge Devices
Besides the MCU, non-volatile memory is another important factor in designing an edge device that does ML processing. Embedded flash is an obvious choice, if the MCU provides sufficient e-flash for the application software. As MCU technology nodes keep shrinking, however, e-flash becomes more difficult to integrate. Simply put, the application software outgrows the available e-flash. External standalone NV flash becomes necessary in such cases. Considering reliability, read throughput, and Execution-in-Place capabilities from different kinds of NV flash devices provide, NOR flash memory is often at the top of the list for edge system designers.
To build a secure and reliable edge device for ML, there are many design considerations. The following are a few of them to help designers to make a decision on what NV memory to use (see Figure 4).
1.Secure boot
All embedded systems must boot securely. For edge devices, secure boot is especially important because of the proximity to human access and thus risks of potential security attacks. Typically, for devices using a Store-N-Download (SnD) code model, boot code is stored in non-volatile memory and downloaded to RAM to be executed. If the non-volatile memory is not secure, it is easy for hackers to replace or modify the boot code to perform malicious operations. Thus, storing boot code in secure non-volatile memory and establishing a root-of-trust during boot are very important considerations for edge devices.
2.Resistance to attacks
The attack surface of edge devices is undeniably big, given their connectivity. Even with secure boot, hackers may attempt to steal intelligent secrets or privacy information from the device through various attack methods, such as passive monitoring, active replay attacks, side channel attacks, etc. Using non-volatile memories that are resistant to these attacks can greatly reduce the risks of system exposure.
3.Secure storage for important AI parameters
ML algorithms require memory storage for parameters, such as the set of parameters mentioned above. These parameters are the results of running the training with vast data sample sets. The AI algorithm itself may not be interesting to hackers but the end result often is. If hackers can steal the end result from storage, they can imitate the AI system without going through any training. These parameters, such as the set of parameters, directly affects the ML scheme and the intelligence of the system. Therefore, they should be stored in a secure storage that cannot be altered inadvertently or intentionally by hackers. Non-volatile memories that provide such secure storage capability will be well-suited for edge devices that have sensitive information to store.
4.Fast throughput
Although edge devices may not need a powerful MCU to run extensive ML algorithms, they may still require fast access to non-volatile memory to achieve fast secure boot and good computing performance.

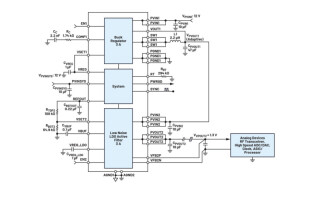
Figure 4: Edge devices using machine learning require non-volatile memory that supports secure boot, resistance to malicious attacks, secure storage, and fast throughput like Cypress Semper Secure NOR Flash memory shown here.
It is an industrial trend to implement intelligence in edge devices so that the processing of user data is closer to its source. Many AI applications can be deployed on edge devices that build smart and user-friendly systems. One of the Machine Learning algorithms, Online Machine Learning, does not require extensive computing power, has great adaptivity to changes, and is suitable for edge devices. To build a smart and secure system on edge devices, users can select non-volatile memories that provide root-of-trust capability, secure storage, fast throughput, and resistance to malicious attacks.
About the Author
Zhi Feng is Senior Principal Applications Engineer in Cypress’ Flash group. He completed his Bachelor degree in EE from South China University of Technology, and his Master of Applied Science degree from University of Ottawa in Canada. He has been with Cypress for 15 years, working in the NOR and NAND memory fields.