
Accelerating processing with Coarse Grain Reconfigurable Arrays
May 01, 2014

Processor acceleration is becoming more important due to increasing performance and low power demands. Research into Coarse Grain Reconfigurable Array...
With increasing performance demands and a push for lower power designs, more efficient methods to perform processing tasks are needed, as throwing more processors at performance issues is no longer viable due to power constraints. Accelerators aim to do computations faster and with lower power consumption, but today's accelerators have shortcomings in power consumption and performance.
The accelerator lineup
Aviral Shrivastava, Associate Professor at Arizona State University's School of Computing, Informatics and Decision Systems Engineering is conducting research into programmable accelerators to enhance today's acceleration technology. Shrivastava lists three common types of accelerators in use today: hardware accelerators, FPGAs, and GPUs. Hardware accelerators dedicate specific compute elements to processing calculations rather than running them on the CPU. They are fast and low power, but not suited for today's quickly changing technology iterations as they aren't programmable. FPGAs are programmable – developers can program any logic onto them and they can act as accelerators – but Shrivastava says they're often too generic and consume too much power. GPUs are popular accelerators today, but they can only accelerate parallel loops, and not all applications use parallel loops.
Coarse Grain Reconfigurable Arrays
Shrivastava is working on developing Coarse Grain Reconfigurable Arrays (CGRAs) that can accelerate non-parallel loops and enable more accelerating functionality on top of GPUs' parallel loop strengths. CGRAs consist of a two-dimensional mesh of Processing Elements (PEs) made of Arithmetic Logic Units (ALUs) and registers that receive input and instructions, compute the instructed arithmetic or logic operation, and send the output to its four neighbors to compute the next step (Figure 1).
|
|
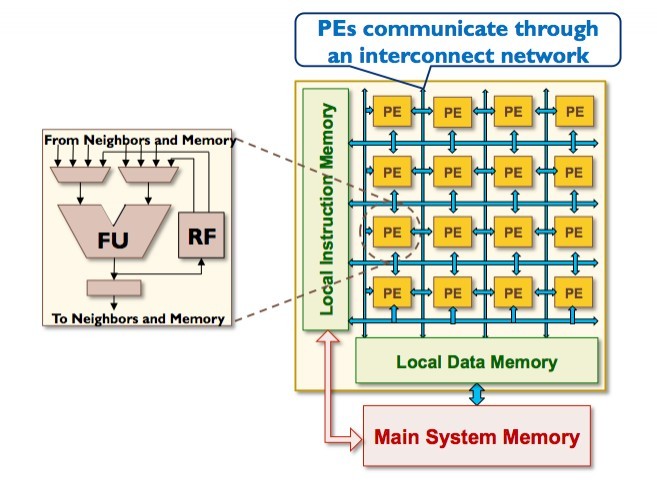
CGRAs' potential comes from their ability to perform an operation while spending very little power. Executing an addition operation in a regular processor requires a lot of power: it has to flow through more than 20 stages of pipeline. In a CGRA, power is needed only to get the operands from neighbors and to perform the addition operation. CGRAs can accelerate by pipelining – the operations of the loop are laid out on the PEs of the CGRA, and the data flows between them.
CGRAs themselves aren't new, but developers program existing CGRAs to do only one type of computation. The challenge is in mapping, Shrivastava says, as loop kernels need to be mapped onto the CGRA, operations mapped to nodes, and data dependences mapped onto the CGRA's paths. Shrivastava's goal is to remove time-consuming manual coding and enable any type of loop or computation to be mapped to the CGRA by a compiler, a relatively new method. He is developing a compiler toolchain that generates mapping code.
Shrivastava says the CGRA research has interested IBM, who wants to apply this sort of method to parallel-loop-light server applications. Graphics and high-performance computing for scientific research and multimedia extensions can also gain from using CGRAs.
Taming the branch divergence problem
A challenge faced by all existing acceleration technologies is that of "branch divergence." When executing a loop that has an "if-then-else" construct, the accelerator allocates resources to execute instructions from both paths of the branch – the true path, and the false path – then discards the effects of the false path's instructions. FPGAs map the functionality from both paths on computational resources, and GPUs execute instructions from both branch paths and discard the results of the false path instructions. Accelerators have to do this because the outcome of the branch is not known at compile-time when branch path resources are allocated (the outcome of the branch is computed at runtime, when the branch is executed). This redundant execution causes the branch to take double the performance time and power to execute.
In a paper accepted at the Design Automation Conference (DAC) and set to be published in June, Shrivastava and his team propose a solution to the branch divergence problem through smart hardware-software co-design. Instead of allocating some PEs for the true path and some for the false path, the same PEs are assigned to execute instructions from both paths. The instructions from both the true path and from the false path are issued to the PE. At runtime the PE selects only the correct one to be executed.




