
MLPerf Training Evaluates Execution Timings of the Deployed Machine Learning Models
December 20, 2021
Blog

Machine learning (ML) requires industry-standard performance benchmarks to aid in the creation and competitive assessment of the numerous ML-related software and hardware solutions.
However, unlike other domains, ML training has three distinct benchmarking challenges:
- Optimizations that improve training throughput can increase time to solution.
- Training is stochastic and time-to-solution has a high variance.
- Software and hardware systems are so diverse that fair benchmarking with the same binary, code, and even hyperparameters is difficult.
MLcommons' machine learning benchmarking solution, MLPerf, is designed to address these issues. MLPerf's efficacy in driving performance and scalability improvement is statistically evaluated in two sets of data from various manufacturers.
The MLPerf aims to provide a representative benchmark suite for machine learning that properly measures system performance in order to achieve five high-level goals:
- Allow for a fair comparison of rival systems while yet promoting machine learning innovation.
- Make ML development faster by measuring it in a fair and relevant way.
- Ensure repeatability for consistent findings.
- Provide services to both the business and academic groups.
- Keep benchmarking costs low so that everyone may participate.
MLPerf creates a benchmark suite that includes a variety of applications, DNN models, and optimizers. It also accurately specifies models and training techniques to create reference implementations of each benchmark. MLPerf establishes time restrictions to reduce the impacts of stochasticity while comparing the findings. Moreover, it allows the ML and systems communities to examine and duplicate the results by making the submission code open source.
Each benchmark calculates the amount of time it takes to train a model on a given dataset in order to attain a given quality goal. Final results are generated by measuring the benchmark a benchmark-specific number of times, removing the lowest and highest values, and averaging the remaining results to account for the large diversity in ML training durations. Even the average number of results isn't enough to eliminate all volatility. The results of imaging benchmarks are typical +/- 2.5 percent, whereas other benchmarks are often +/- 5%.
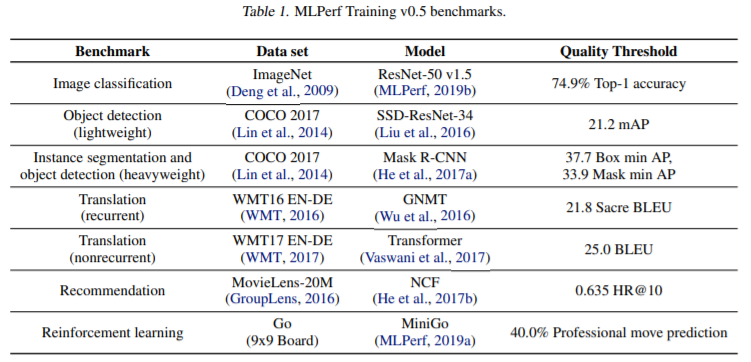
Credits: arxiv
MLPerf hopes to stimulate innovation in both software and hardware by enabling submitters to reimplement the reference implementations. MLPerf has two divisions that provide varying amounts of reimplementation freedom. The Closed division demands the use of the same model and optimizer as the reference implementation in order to compare hardware platforms or software frameworks, "apples-to-apples." The Open division aims to promote quicker models and optimizers by allowing any machine learning technique to achieve the desired quality.
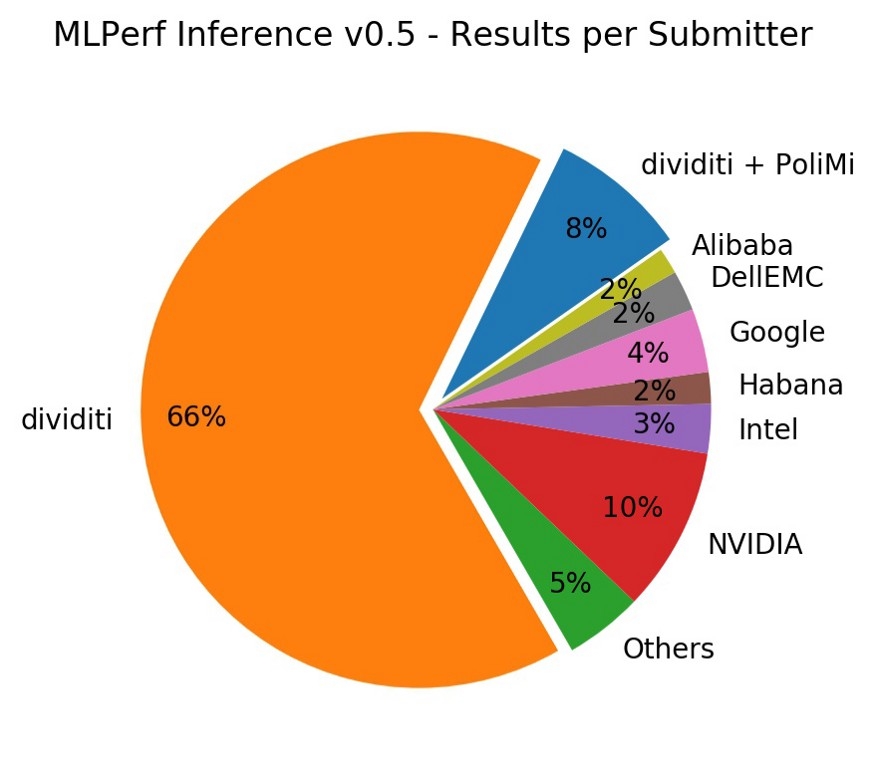
Credit: Medium
Industry Benchmark for ML Systems
To summarize, MLPerf Training is a collection of machine learning benchmarks that cover both commercial and academic applications. It has made few contributions, despite being the only widely used ML-training benchmark suite with such comprehensive coverage. Firstly, system comparisons for equivalent workloads are made possible by the precise definition of model architectures and training procedures for each benchmark feature. Furthermore, to address the challenges of benchmarking ML training, reference implementations and rule definitions are used. The stochastic nature of training processes, the need to train to completion in order to determine the quality impact of performance optimizations, and the need for workload variation at various system scales, are a few challenges.
Although MLPerf focuses on relative system performance, as evidenced by the online results, it also provides general lessons in ML and benchmarking. The size of a real data set is crucial for ensuring realistic memory-system behavior. For example, the initial NCF data set was far too small to fit entirely in memory. Moreover, when benchmarking data sets smaller than industrial scale, training time should not include startup time, which is proportionally less in real-world use.
Thus, MLPerf is quickly establishing itself as the industry benchmark for ML systems, as well as an ideal forum for announcing new products with benchmarking results that analysts, investors, and buyers can rely on.
You can head over to the official website of ML Commons for more information.

Saumitra Jagdale is a Backend Developer, Freelance Technical Author, Global AI Ambassador (SwissCognitive), Open-source Contributor in Python projects, Leader of Tensorflow Community India, and Passionate AI/ML Enthusiast.



