
Performance management: A new dimension in operating systems
April 01, 2010

Performance resources such as CPU cycles, clock speed, memory and I/O bandwidth, and cache memory space should be managed simultaneously to optimize p...
Processors perform as well as OSs allow them to. A computing platform, embedded or otherwise, consists of not only physical resources – memory, CPU cores, peripherals, and buses – managed with some success by resource partitioning (virtualization), but also performance resources such as CPU cycles, clock speed, memory and I/O bandwidth, and main/cache memory space. These resources are managed by ancient methods like priority or time slices or not managed at all. As a result, processors are underutilized and consume too much energy, robbing them of their true performance potential.
Most existing management schemes are fragmented. CPU cycles are managed by priorities and temporal isolation, meaning applications that need to finish in a preset amount of time are reserved that time, whether they actually need it or not. Because execution time is not safely predictable due to cache misses, miss speculation, and I/O blocking, the reserved time is typically longer than it needs to be. To ensure that the modem stack in a smartphone receives enough CPU cycles to carry on a call, other applications might be restricted to not run concurrently. This explains why some users of an unnamed brand handset complain that when the phone rings, GPS drops.
Separate from this, power management has recently received a great deal of interest. Notice the “separate” characterization. Most deployed solutions are good at detecting idle times, use modes with slow system response, or particular applications where the CPU can run at lower clock speeds and thus save energy. For example, Intel came up with Hurry Up and Get Idle (HUGI). To understand HUGI, consider this analogy: Someone can use an Indy car at full speed to reach a destination and then park it, but perhaps using a Prius to get there just in time would be more practical. Which do you think uses less gas? Power management based on use modes has too coarse a granularity to effectively mine all energy reduction opportunities all the time.
Ideally, developers want to vary the clock speed/voltage to match the instantaneous workload, but that cannot be done by merely focusing on the running application. Developers might be able to determine minimum clock speed for an application to finish on time, but can they slow down the clock not knowing how other applications waiting to run will be affected if they are delayed? Managing tasks and clock speed (power) separately cannot lead to optimum energy consumption. The winning method will simultaneously manage/optimize all performance resources, but at a minimum, manage the clock speed and task scheduling. Imagine the task scheduler being the trip planner and the clock manager as the car driver. If the car slows down, the trip has to be re-planned. The driver might have to slow down because of bad road conditions (cache misses) or stop at a railroad barrier (barrier in multithreading, blocked on buffer empty due to insufficiently allocated I/O bandwidth, and so on). Applications that exhibit data-dependent execution time also present a problem, as the timing of when they finish isn’t known until they finish. What clock speed should be allocated for these applications in advance?
An advanced performance management solution
One example of managing performance resources is VirtualMetrix Performance Management (PerfMan), which controls all performance resources by a parametrically driven algorithm. The software schedules tasks, changes clock speed, determines idle periods, and allocates I/O bandwidth and cache space based on performance data such as bandwidth consumed and instructions retired. This approach (diagrammed in Figure 1) solves the fragmentation problem and can lead to optimum resource allocation, even accounting for the unpredictability of the execution speed of modern processors and data-dependent applications.
|
|

The patent-pending work performed allocation algorithm uses a closed-loop method that makes allocation decisions by comparing work completed with work still to be performed, expressed in any of the measurable performance quantities the system offers. For example, if the application is a video player or communication protocol that fills a buffer, PerfMan can keep track of the buffer fill level and determine the clock speed and time to run so that the buffer is filled just in time. The time to finish will inevitably vary, so the decision is cyclically updated. In many cases, buffers are overfilled to prevent blocking on buffer empty, which can lead to timing violations. PerfMan is capable of precise performance allocation, keeping buffering to a minimum and reducing memory footprint. The algorithm can handle hard, soft, and non-real-time applications mixed together.
If the application execution graph is quantified into simple performance parameters and the deadlines are known when they matter, the algorithm will dynamically schedule to meet deadlines just in time. Even non-real-time applications need some performance allocation to avoid indefinite postponement. Allocating the minimum processor resources an application needs increases system utilization, resulting in a higher possible workload. The method does not rely on strict priorities, although they can be used. The priority or order in execution is the direct result of the urgency the application exhibits while waiting its turn to run, which is a function of the basic work to be performed/worked completed paradigm.
Extending to more dimensions
If tasks are ready to run in existing OSs, they will run, but do they need to? Can they be delayed (forced idling) if the OS knows it will not affect their operation?
Knowing the timing of every task and whether it is running or waiting to run with respect to its progress toward completion allows the software to automatically determine the minimum clock speed and runtime. Thus everything completes on time under all load conditions. Matching clock speed to the instantaneous workload does not mean the clock speed is always minimized. The goal of low energy consumption sometimes calls for a burst of high speed followed by idle, as in Intel’s HUGI. But even then, there is no benefit in running faster than the optimum utilization (executed operations per unit of time) would indicate. Fast clocking while waiting for memory operations to complete does not save energy.
The algorithm’s mantra of “highest utilization/workload at the lowest energy consumption” is largely accomplished with a closed-loop algorithm managing all performance resources.
In multicore systems, a balanced load, low multithreading barrier latency, and the lowest overall energy consumption cannot be achieved simultaneously. To resolve this, PerfMan can be configured to optimize one or several performance attributes. If minimum energy consumption is the goal, an unbalanced system with some cores that are highly loaded and others that are empty and thus shut down might offer the lowest energy consumption at the expense of longer execution latency and overall lower performance.
Accelerating threads to reduce barrier latency can also lead to higher energy consumption. However, meeting deadlines (hard or soft) overrides all other considerations. The precise closed-loop-based performance resource allocation algorithm can safely maintain a higher workload level, which in turn, allows pushing the core consolidation further than possible with existing methods and thus achieving higher energy reduction.
Implementation on VMX Linux
PerfMan has been implemented as a thin kernel (sdKernel) running independently of the resident OS. It has been ported to Linux 2.6.29 (VMX Linux), as shown in Figure 2. An Android port is nearing completion. The software takes over Linux task scheduling and interworks with the existing power management infrastructure. A separate version of the sdKernel provides virtualization and supports hard real-time tasks in a POSIX-compliant environment. Scheduling/context switching is at the submicrosecond level on many platforms, but because most Linux system calls are too slow for hard real-time applications, the sdKernel provides APIs for basic peripherals, timers, and other resources.
|
|
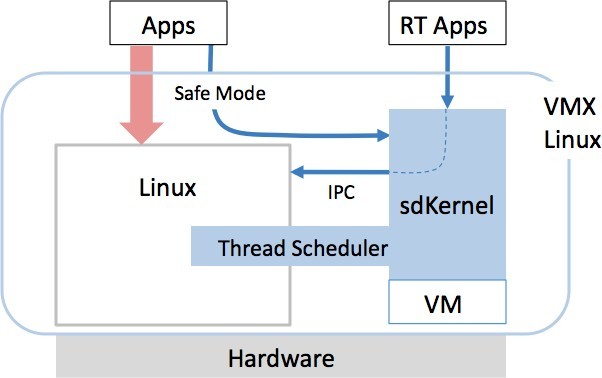
By monitoring performance, the software can detect unusual execution patterns that predict an upcoming OS panic and crash. In such cases, the sdKernel will notify mission-critical applications to stop using Linux system calls and temporarily switch over to sdKernel APIs (safe mode) while Linux is being rebooted.
VMX Linux supports a mix of real and non-real-time applications with efficient performance isolation while minimizing energy consumption. It can also provide hardware isolation/security and safe crash landing.
Benchmarks show the results
The energy consumption, measured in real time using a VMX-designed energy meter, was accumulated for the system and correlated to individual applications. A media player application (video and audio) was run on an OMAP35xx BeagleBoard first using standard Linux 2.6.29 (Figure 3 red graph) and then VMX Linux (Figure 3 blue graph).
|
|

Performance compliance (Perf Compl graph) shows how close the application tasks come to finish on time (center line). Below the line indicates deadline violations. Notice that with VMX Linux, a 95 percent average load is achieved with no prebuffering and no deadline violations, but it gets close. The total board energy consumption for the 46 seconds of video dropped from 68.7 W*sec to 27.6 W*sec with VMX Linux. The displayed data represents averages over a preset interval. As an additional bonus, when Linux is purposely crashed, the video disappears but the music plays on in safe mode with no audible glitches.
In short, the implementation creates a new approach to performance management with exciting results.
VirtualMetrix 858-395-5793 | [email protected] www.virtualmetrix.com




