
Demystifying AI and Machine Learning for Digital Health Applications
March 14, 2019
Story

In this article, we?ll take a closer look at the overall architecture of algorithms for processing physiological signals and demystify its operations.
The first wave of FDA-approved wearable digital health monitors integrated with consumer products such as smart watches are just becoming available. Medical sensor technology continues to advance at a rapid pace, allowing compact, cost-effective, and increasingly accurate physiological sensors to make their way into off-the-shelf wearable devices. One of the real drivers of this transformation is the availability of cutting-edge machine learning and AI algorithms that can extract and interpret meaningful information from vast troves of data. This includes noisy data and not-so-perfect signals (such as ECG data from a smart watch) corrupted with various artifacts that are hard to process using traditional algorithms that tend to be deterministic and rules based.
Until recently, unlocking the secrets in a physiological signal coming from these sensors to form reasonably accurate decisions acceptable for regulatory submissions was challenging and often impossible. Advances in machine learning and AI algorithms are now enabling engineers and scientists to overcome many of these challenges. In this article, we’ll take a closer look at the overall architecture of algorithms for processing physiological signals and demystify its operations, turning it into more real-world engineering founded in decades of research.
To illustrate the power of a simple machine learning algorithm, here’s an online video that describes how the data from an accelerometer in an activity tracker can predict the various states of motion or rest of the wearer. We can extend this approach to more complex real-world medical signals such as ECG and develop algorithms that can automatically classify ECG signals as normal or exhibiting atrial fibrillation.
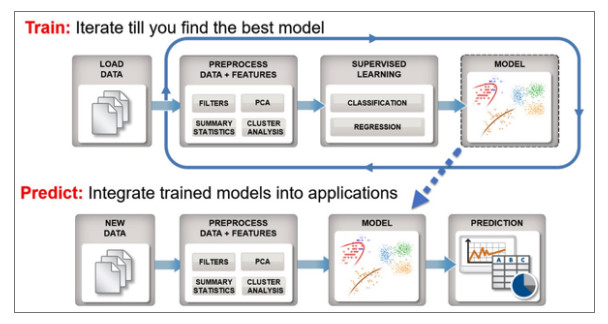
Developing machine learning algorithms consists of two primary steps (Figure 1). The first step in this workflow is feature engineering, where certain numerical/mathematical features from the data set of interest are extracted and presented to the subsequent step. In the second step, the extracted features are fed into a well-known statistical classification or a regression algorithm such as a support vector machine or a traditional neural network configured appropriately to come up with a trained model that can then be used on a new data set for prediction. Once this model is iteratively trained using a well-represented labelled dataset till a satisfactory accuracy is achieved, it can then be used on a new dataset as a prediction engine in a production environment.
So how does this workflow look for an ECG signal classification problem? For this case study, we turn to the 2017 PhysioNet Challenge dataset, which uses real-world single-lead ECG data. The objective is to classify a patient’s ECG signal as one of the four categories: Normal, Atrial Fibrillation, Other Rhythm, and Too Noisy. The overall process and the various steps for tackling this problem in MATLAB are shown in Figure 2.
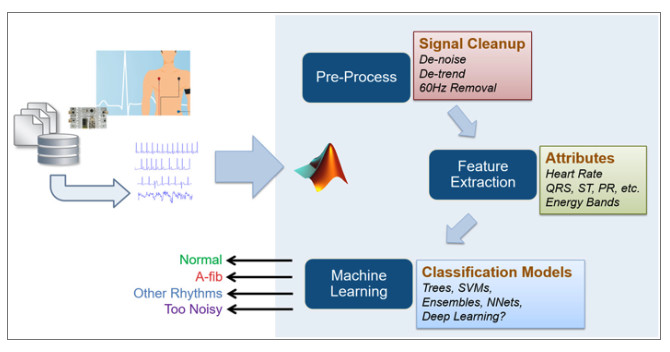
Preprocessing and Feature Engineering
The feature engineering step is perhaps the hardest part in developing a robust machine learning algorithm. Such a problem cannot simply be treated as a “data science” problem, as it is important to have the biomedical engineering domain knowledge to understand the different types of physiological signals and data when exploring the various approaches in solving this problem. Tools such as MATLAB bring the data analytics and advanced machine learning capabilities to the domain experts and enable them to focus on feature engineering by making it easier to apply “data science” capabilities such as advanced machine learning capabilities to the problems they are solving. In this example, we use advanced wavelets techniques for signal processing to remove noise and slow-moving trends such as breathing artifacts from the dataset and extract various features of interest from the signals.
Developing the Classification Model
The Classification Learner App in Statistics and Machine Learning Toolbox is a particularly effective starting point for engineers and scientists that are new to machine learning. In our example, once a sufficient number of useful and relevant features are extracted from the signals, we use this app to quickly explore various classifiers and their performance and narrow down our options for further optimization. These classifiers include decision trees, random forests, support vector machines, and K-nearest neighbors (KNN). These classification algorithms enable you to try out various strategies and choose the ones that provide best classification performance for your feature set (typically evaluated using metrics such as confusion matrix or an area under ROC curve). In our case, we very quickly achieved ~80 percent overall accuracy for all the classes, simply following this approach (the winning entries for this competition scored around 83 percent). Note that we have not spent much time on feature engineering or classifier tuning, as our focus was on validating the approach. Typically, spending some time on feature engineering and classifier tuning leads to significant further improvement in classification accuracy. More advanced techniques such as deep learning can also be applied to such problems where the feature engineering and extraction, and classification steps are combined in a single training step, though this approach typically requires a much larger training dataset for this to work well compared to traditional machine learning techniques.
Challenges, Regulations, and Future Promises
While many of the commonly available wearable devices are not quite ready to replace their FDA-approved and medically validated counterparts, all technology and consumer trends are strongly pointing in that direction. The FDA is starting to play an active role in simplifying regulations and encouraging the evolution of regulatory science specifically through initiatives such as the Digital Health Software Precertification Program and modeling and simulation in device development.
The vision of human physiological signals collected from daily use wearables becoming the new digital-biomarkers that can provide a comprehensive picture of our health is becoming more real now than ever, in large part due to the advances in signal processing and machine learning and deep learning algorithms. Workflows enabled by tools such as MATLAB are enabling medical devices’ domain experts to apply and utilize data science techniques such as machine learning without having to be experts in data science.
Arvind Ananthan is the Global Medical Devices Industry Manager at MathWorks. He works closely with medical device engineers, academic researchers in this community, and regulatory authorities including the FDA to understand and address the challenges and needs of this industry covering areas of modeling, simulation, and data analytics. He has over 15 years of experience in a variety of technical and business roles. He holds a Master of Science degree in Electrical Engineering from University of Maryland Baltimore County with a focus on statistical signal processing and neural networks.



