
Low power solutions for always-on, always-aware voice command systems, part 3
May 24, 2018
Story

Recent advances in hardware and software have made it possible for compact, battery-powered products to include always-on voice command systems.
This is part three of a three part series. Read part two here.
Recent advances in hardware and software have made it possible for compact, battery-powered products to include always-on voice command systems, which have already proven their reliability and appeal in tens of millions of smart speakers. This paper describes new applications, techniques, hardware, and software that will make these products possible.
Software algorithms for voice command in portable products
The algorithms that allow always-on, always-listening voice command products to function are necessarily complex. They must be alert for the wake word 24/7/365; recognize the wake word reliably; isolate as best as possible the user’s voice from the surrounding noise; and produce a signal that is clean enough for the voice recognition engine to use. There are many different algorithms at work, all of which must be tuned to suit the product’s design and application. The design and power consumption demands of portable products may affect the function of these algorithms.
Basic algorithm structure
Here are the basic components of a voice command algorithm package. Here they are, presented in order from the microphone end to the final signal output.
Sound detector: Typically, the signal from a single microphone is monitored using a comparator. When the signal level exceeds a certain threshold—such as when a user speaks the wake word—the comparator sends a command to power up the rest of the system. This function may not be necessary in home products, in which power consumption is not as much of an issue and more of the system can be powered up at all times, but it is critical to portable products because it allows more components to be shut down to save power. This function must also occur quickly so that the system is able to receive the wake word. For example, with Vesper VM1010 cited above, the microphone wakes up within 50 µs, much less that the time it takes to utter the first letter in any keyword.
Noise reduction and filtering: To improve the sound detection function, it helps to filter out sounds, such as noise from autos, HVAC systems and wind, that are obviously not human voices and thus safe for the voice recognition system to ignore. Through choice of microphones, physical design of the product or audio processing, the product can (as with the Vesper VM1010 microphone cited above) filter out sounds outside the human vocal range (which spans roughly 100 Hz to 6 kHz). Audio processing can also remove repetitive sounds, such as refrigerator noise. However, these functions may require the processor to be powered on, which may impact battery life of portable products.
Wake word detection: Once the system detects sound and powers up, it must record the incoming audio and compare it to a stored digital file of the wake word (such as “Alexa” for the Amazon Echo). If the waveform of the incoming audio is sufficiently close to the stored file, the device becomes receptive to voice commands.
Direction of arrival detection: In order for a microphone array to focus on a user’s voice, it must first determine where the user is relative to the product. The processor determines the direction of arrival by comparing the phase information of the signals from the microphones. It must also include precedence logic that rejects reflections of the user’s voice from nearby objects, and it must adjust its operating threshold to compensate for ambient noise level, so environmental noise does not create false directional cues. Note that direction of arrival determination may not be necessary in products such as earphones, in which the physical position of the user’s mouth relative to the microphone array is already known.
Beamforming: The reason for a microphone array is that the signals from the multiple microphones can be processed so that the array becomes directional; sounds coming from the determined direction of arrival are accepted while sounds coming from different directions are rejected. With some products, such as earphones and automotive audio systems, the direction of the user’s voice relative to the microphone array is known, so the beamformer’s direction may be permanently fixed. In devices such as smart speakers, remote controls and home automation wall panels, the desired direction of focus for the beamformer will have to be determined and the response of the array adjusted to focus in the direction of the user.
Acoustic echo cancelling (AEC): Acoustic echo cancelling rejects the sounds (such as music or announcements) coming from the device itself, so that the array can pick up the user’s voice more clearly. Because the original signal and the response of the device’s internal speaker are known, the signal that comes back through the microphone can be rejected. However, the echoes of this sound from surrounding objects—which is time-delayed and altered in frequency content—must also be rejected. AEC is not necessary in products such as headphones and earphones, because the sound coming from the product’s speakers is confined and typically not enough of it leaks out to affect the performance of the product’s microphones.
Local command set recognition: Because portable products may not be able to rely on an Internet connection as today’s smart speakers do, they will likely need to recognize a certain number of basic function commands on their own, without the help of external servers. These commands are typically limited to basic functions such as play, pause, skip tracks, repeat and answer call. Recognition of these commands works in the same way as wake word detection does. However, even though the command set is limited, the need for local command set recognition increases the load on the processor compared with a home smart speaker that needs to recognize only its wake word, and offloads other voice recognition tasks to an external, Internet-connected server.
Algorithm tuning
The function of each of the above algorithms is complex, and must be adjusted to suit the application—especially in portable products, where the environment and use patterns are likely to be different from those of home products. Here are the algorithm functions that must be tuned for optimum voice recognition accuracy.
Detection/wake threshold: The threshold levels for sound detection and wake word detection must be set high enough to minimize false triggering of the device, but low enough that the user can address the device at a normal speaking level. In portable products, especially, it may be desirable for these levels to be adjusted dynamically, so the performance adjusts to compensate for varying levels of ambient sound. The function of the dynamic compensation will itself have to be tuned.
Noise reduction/cancelling: Depending on the application, different types of noise may be encountered, and the device can be tuned to reject them. For example, the spectrum of any given car’s road and engine noise at different speeds is known by the manufacturer, so the voice recognition system can be tuned to reject these sounds. The noise reduction/cancelling algorithms can also function dynamically, adapting to the changing environment, but this dynamic function must also be tuned.
Beamformer beamwidth: The tighter the beamwidth of the beamformer, the better it will reject environmental sounds and reflections of the user’s voice from other objects. However, setting beamwidth too tight will cause the unit to reject the user’s voice if the user moves slightly. In products such as earphones and headphones, where the direction of arrival of the user’s voice does not vary, beamwidth may be set tightly, but in products such as remote controls and home automation panels, it will have to be set wider to accommodate movement of the user while the user is speaking.
Wake/sleep strategies: As suggested previously, one of the goals when minimizing power consumption is to put the device to sleep as often as possible, and to keep it asleep for as long as possible. However, this goal requires tradeoffs. If the device is put to sleep too quickly after use, it may miss commands that follow the wake word, and require the user to speak the wake word again, which will likely frustrate users. If the device is kept awake longer than necessary, it will consume more power than it needs to.
DSP Concepts’ Voice UI algorithms are specifically designed to make it easy to tune all of the above functions, and to create custom processing configurations to suit any portable or battery-powered voice command product. Signal processing chains can be configured through a simple graphical interface, using any combination of more than 400 available processing modules (Figure 1). These modules can be tuned through familiar onscreen knobs and buttons, in the same intuitive way that a rack-mount audio processor is typically adjusted.
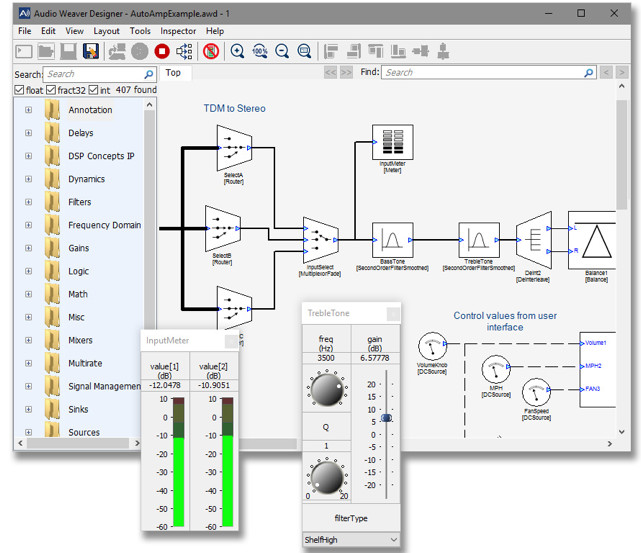
[Figure 1 | Screen image showing graphical configuration of an audio processing chain using DSP Concepts Voice UI]
Because of power consumption demands and form factor limitations, the capabilities of the audio processors used in most portable products are typically less than those of the processors used in home products. Thus, product design teams must be cautious not to exceed the available processing power when designing signal chains for voice command products. Yet achieving the best possible performance demands they make the most use of what processing is available. Because DSP Concepts Voice UI algorithms are already optimized for the processors they run on, they do not need to be rewritten to suit a particular processor, and debugging is not necessary. Signal chains can be tested in real time, and also tested for different processors, which makes choosing the right processor for the application much easier and faster.
The tunability and versatility of DSP Concepts Voice UI results in demonstrable performance advantages, which can be seen in demonstration videos on the DSP Concepts website.
Conclusion
The challenges of creating always-on voice command products that can run for many hours to many months on battery power—while achieving functionality similar to that of today’s popular smart speakers—are considerable. But thanks to the products described in this paper, these challenges are now manageable. The proper choice of components, combined with careful tuning to suit the application, can result in portable voice command products that deliver a satisfying and reliable experience for consumers. It will be interesting to see what new functions, conveniences and capabilities these technologies will bring to tomorrow’s portable and battery-powered tech products.



